![]()
![]()
![]()
![]()
![]()
![]()
SFX - un acronimo che è anche un gioco di parole derivante da special effects - è il nome che è stato dato ad un progetto pluriennale a più stadi, portato avanti dall'Università di Gand in Belgio e di Los Alamos in USA, e che ha coinvolto un buon numero di partner commerciali. Tale progetto è documentato attraverso una serie di articoli sulla rivista on line D-Lib Magazine, che in questa breve esposizione si tengono soprattutto presenti (e che a partire da agosto 2002 saranno a disposizione in traduzione sulle pagine web della CNUR, la Commissione Nazionale Università e Ricerca dell'AIB).
Lo scopo del progetto è stato produrre un software (un "componente di servizio") che permetta ad una istituzione (diciamo una digital library o una hybrid library) di creare un ambiente informativo interconnesso, cioè di stabilire link tra le varie risorse elettroniche (a pagamento o ad accesso libero) che costituiscono la sua collezione, indipendentemente dalle connessioni previste a priori da ogni risorsa. Ciò permette che un utente, effettuata una ricerca su una risorsa (detta origin) ed ottenuta una risposta, possa richiedere, per un certo record o citazione o entità informativa bibliografica (che diventa la link-source), dei cosiddetti "servizi estesi", cioè collegamenti rilevanti ad altre risorse della collezione (che saranno dette target). Dal punto di vista della specifica istituzione, l'obiettivo è stato la disponibilità di un software in grado di offrire un punto unico di gestione di link a servizi estesi da essa stessa definiti.
Per servizi estesi rispetto ad una certa entità informativa bibliografica si intende, per esempio:
Scendendo maggiormente nel dettaglio, il progetto SFX ha prodotto:
Attualmente, il nome SFX definisce l'implementazione proprietaria di Ex Libris, e SFX server è il componente di servizio di Ex Libris; il componente di servizio free software viene denominato semplicemente OpenURL resolver (anzi: OpenResolver).
Non è facile capire fin dove è pura questione di nomi: scorrendo i dettagliati resoconti di Van de Sompel sulla sperimentazione, pare proprio che essa sia pienamente confluita nel software proprietario SFX, e che l'OpenResolver di UKOLN sia molto più semplice nell'architettura e limitato nelle funzionalità, seppur sviluppabile secondo la filosofia del free software [1].
E' possibile farsi un'idea concreta del funzionamento di SFX attraverso alcune demo disponibili in rete, raccolte al sito:
<http://library.caltech.edu/openurl/Demos.htm>. Si vedano in particolare OpenResolver di Ukoln e SFX di Ex Libris, per il quale si veda anche <http://www.sfxit.com/>.
Anche solo mediante le demo, si può dunque vedere che il processo avviene in tre tempi e attraverso tre passaggi successivi:
à dietro quel bottone c'è una particolare URL, la OpenURL, che al momento del "click" verrà inviata al componente di servizio dell'utente; perché si abbia questo, è necessario che la risorsa di partenza sia OpenURL compliant, cioè in grado di emettere una OpenURL, opportunamente formattata e opportunamente indirizzata (cioè indirizzata di volta in volta al componente di servizio specifico per l'utente);
à attivando il bottone SFX si realizza dunque l'invio della OpenURL al componente di servizio (o al risolutore di OpenURL): ad esso la OpenURL porta come parametri i metadati della link-source [2], utilizzando i quali il componente di servizio può attuare il processo di verifica concettuale o valutazione SFX (cioè il confronto con la base SFX) e selezionare i servizi possibili, cioè una serie di link potenziali, attivabili singolarmente cliccando l'apposito bottoncino;
à dietro ogni bottoncino relativo ad un servizio proposto, ci sono i parametri per lo script targetParser: con il click su di esso, viene attivato un programma (lo script targetParser, per l'appunto) che implementa le procedure link-to per il target proposto e conduce l'utente il più vicino possibile all'elemento informativo pertinente.
Seguendo la falsariga degli articoli di Van de Sompel, si ha l'opportunità di seguire il percorso sperimentale e di apprezzarne il metodo, che procede per implementazioni concrete e generalizzazioni progressive. Infatti:
Qui di seguito si cerca pertanto di delineare sincronicamente i principali nodi affrontati e di descrivere il funzionamento del componente di servizio nella sua architettura definitiva.
In sintesi il progetto è consistito:
Scendendo nei dettagli:
|
Source (punto di partenza) |
servizio del Colli |
target (punto di arrivo) |
|
APS/PROLA |
abstract |
Inspec |
|
BIOSIS |
abstract |
Medline |
|
BIOSIS |
genome |
Genome Base |
|
Wiley |
abstract |
Medline |
|
Wiley |
cited_reference |
Science Cit. Base |
|
CC |
abstrac |
LiSa |
|
EconLit |
review |
Books in Print |
|
Inspec |
full_text |
Springer |
Questo comporta la necessità di mantenere una base di conoscenza, che repertori per ogni risorsa non solo tutte le sue possibili implementazioni, ma anche l'elenco degli oggetti che contiene (per esempio delle riviste spogliate o possedute in full-text, l'anno di inizio del full-text, etc.); e che tali "soglie globali" siano sovrascrivibili da "soglie locali" che descrivono il contesto di una singola istituzione.
Per chiarezza si riporta qui la figura n. 7 del terzo articolo di Van de Sompel:

Attraverso una schematizzazione grafica è possibile riepilogare forse più agevolmente i vari passaggi e la successione delle schermate del processo SFX.
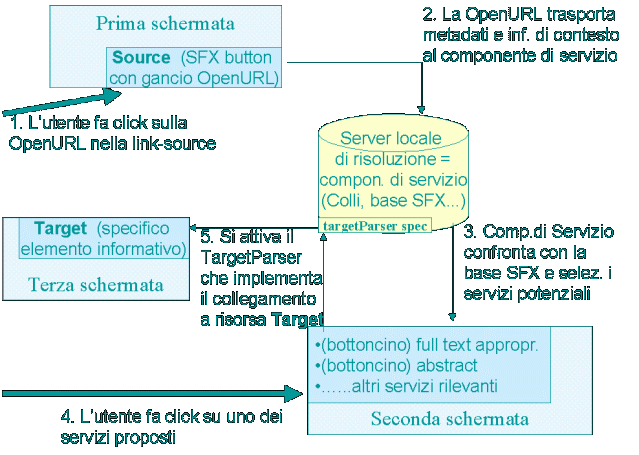
Sotto il bottone SFX, che una risorsa OpenURL compliant presenta all'utente per ogni citazione bibliografica, c'è una OpenURL: essa è costituita da una BASE-URL (cioè un indirizzo web, che è quello del componente di servizio, che garantisce la contex-sensitiveness) e una QUERY, che contiene la serie di parametri passati al componente di servizio, formattati secondo lo standard.
La proposta dello standard OpenURL è probabilmente il principale conseguimento del progetto: invece del proxying o di altro modo ad hoc per catturare i metadati della risorsa, si è scelto di sollecitare la collaborazione dei fornitori di informazione, ai quali si chiede di includere nei propri record, invece di più link chiusi, un solo "gancio" costruito secondo un ben preciso standard. Si chiede perciò ad ogni risorsa di rendersi SFX aware o OpenURL compliant, introducendo, nel record che presenta all'utente, una OpenURL, cioè un bottone cliccabile, che, attivato, punta al componente di servizio (o risolutore di OpenURL) e gli passa i metadati in formato predefinito (di nuovo: la risorsa di partenza OpenURL compliant deve poter proporre ad ogni utente un bottoncino che punti esattamente al suo componente di servizio).
Quando al componente di servizio arriva la OpenURL, esso (anzi, per la precisione il sottomodulo chiamato "componente di reindirizzamento" [3]) è in grado di integrare i metadati attraverso l'attivazione dell'apposito script sourceParser [5].
Ricevuta ed eventualmente integrata l'informazione suddetta, il componente di servizio la trasforma in un oggetto di rappresentazione interna normalizzata, per poi passarla nel processo valutativo SFX attuato per confronto con la base SFX, costituita dalla tabella Colli e dalle soglie. In questo processo, vengono selezionati (col Colli) e filtrati (con le soglie) i servizi pertinenti per tale link-source (in funzione dell'origine, del tipo di documento, e di altri metadati presenti nelle soglie quali l'ISSN o l'annata); ogni servizio è implementato verso determinati target: in questo modo può accadere che determinate link-source si trovino in connessione con determinati target anche imprevedutamente.
Il componente di servizio, per svolgere la sua funzione di servizio di linking sofisticato, non utilizza un database di identificatori (del tipo, per esempio: "tal DOI -> tale URL"), bensì un database di connessioni logiche ("tale risorsa -> tale servizio"), il che richiede che esso sia in grado di lavorare con i metadati e non solo con gli identificatori; detto in altro modo, richiede che i metadati siano utilizzati non solo come identificatori ma come operatori per delle procedure.
A questo punto viene presentata la schermata SFX all'utente, con l'elenco dei servizi selezionati, che è una serie di link concettualmente verificati ma non risolti: al click su di essi, si attiva il targetParser specifico per risorsa, che conduce l'utente nella risorsa target, il più vicino possibile all'elemento specifico desiderato. Lo script targetParser riceve infatti alcuni parametri (identificatore dell'oggetto GenericRequest che rappresenta la citazione, il servizio del Colli con relativo target, alcuni metadati), che utilizza per implementare le procedure link-to per il target proposto: produce cioè una URL verso la risorsa target che implementa la sintassi di puntamento interna specifica per la risorsa (o, se essa non esiste, la sintassi di ricerca) in modo tale da condurre l'utente il più vicino possibile all'informazione pertinente. Ad esempio, se si tratta di reperire il full-text di un articolo, conduce ove possibile al testo pieno e non alla pagina di selezione dei fascicoli. Ma la possibilità di un link più o meno diretto dipende dalla risorsa: ogni target è infatti raggiungibile, ma ad un livello maggiore o minore di profondità in dipendenza dai metadati disponibili e dalla sintassi link-to supportata; i target che non ammettono una sintassi link-to diretta, ammettono di solito una ricerca, anch'essa implementabile tramite il targetParser, la quale è più incerta ma offre il vantaggio di salvaguardare una certa serendipity.
E' evidente che il novero e la qualità dei servizi proposti dipendono da:
La OpenURL è attualmente basata [6] sul protocollo TCP-IP HTTP GET o POST, ma non sono escluse evoluzioni in direzione XML, ed è così strutturata:
La BASE-URL corrisponde alla componente <authority><path> delle specifiche URI e deve ottemperare alle regole ad essa relative sui caratteri riservati. E' la URL di un componente di servizio che può accettare in input una OpenURL.
La QUERY corrisponde al componente query delle specifiche URI.
QUERY ::= DESCRIPTION ( '&&' DESCRIPTION )
DESCRIPTION descrive l'origine dell'oggetto di metadati trasportato + l'oggetto di metadati stesso.
Se ci sono più oggetti, le loro DESCRIPTION devono essere delimitate da 2 & (e commerciale).
DESCRIPTION ::= ( ORIGIN-DESCRIPTION '&' )? OBJECT-DESCRIPTION | OBJECT-DESCRIPTION ( '&' ORIGIN-DESCRIPTION )?
(la QUERY può essere costituita dalla descrizione della link-source e, facoltativamente, della sua risorsa di origine, nell'ordine che si vuole)
ORIGIN-DESCRIPTION ::= sid '=' VendorID ':' databaseID
(altamente consigliato, obbligatorio se si usa la LOCAL-IDENTIFIER-ZONE)
OBJECT-DESCRIPTION ::= ZONE ( '&' ZONE) *
(ci sono 3 tipi di ZONE possibili per descrivere l'oggetto, tutte facoltative, ma almeno una deve esserci)
GLOBAL-IDENTIFIER-ZONE ::= 'id' '=' GLOBAL-NAMESPACE ':' GLOBAL-IDENTIFIER ( '&' 'id' '=' GLOBAL-NAMESPACE ':' GLOBAL-IDENTIFIER)*
GLOBAL-NAMESPACE ::= ( 'doi' | 'pmid' | 'bibcode' | 'oai' )
(può essercene più di uno: quelli ammessi per ora sono: doi, pmid, bibcod, oai)
OBJECT-METADATA-ZONE ::= META-TAG '=' META-VALUE (& META-TAG '=' META-VALUE) *
(i META-TAG ammessi sono 'genre' | 'aulast' | 'aufirst' | 'auinit' | 'auinit1' | 'auinitm' | 'coden' | 'issn' | 'eissn' | 'isbn' | 'title' | 'stitle' | 'atitle' | 'volume' | 'part' | 'issue' | 'spage' | 'epage' | 'pages' | 'artnum' | 'sici' | 'bici' | 'ssn' | 'quarter' | 'date')
LOCAL-IDENTIFIER-ZONE ::= 'pid' '=' VCHAR+
(se c'è, deve esserci anche una ORIGIN-DESCRIPTION)
Per approfondimenti su questi ultimi concetti, si veda lo standard OpenURL.
E' evidente che una certa citazione bibliografica può essere descritta da diverse OpenURL, utilizzando diverse delle possibilità offerte dallo standard. Un esempio dal quarto articolo di Van de Sompel:
Citazione (come si trova in una risorsa informativa):
Moll JR, Olive & M, Vinson C. Attractive interhelical electrostatic interactions in the proline- and acidic-rich region (PAR) leucine zipper subfamily preclude heterodimerization with other basic leucine zipper subfamilies. J Biol Chem. 2000 Nov 3 ; 275(44):34826-32.
doi:10.1074/jbc.M004545200
Esempi di possibili OpenURL che possono essere incluse nella risorsa informativa come mezzo per permettere il linking aperto dalla citazione riportata. Le OpenURL che qui mostrate sono conformi alla bozza corrente di specifiche per la OpenURL. Esse sono codificate come richieste HTTP GET:
http://sfx1.exlibris-usa.com/demo
?sid=ebsco:medline&aulast=Moll&auinit=JR&date=http://sfxserv.rug.ac.be:8888/rug
?id=doi:10.1074/jbc.M004545200Legenda:
<rosso> - BASE-URL del componente di servizio
In un articolo posteriore alla conclusione del progetto e all'avvio dell'iter di standardizzazione, Van de Sompel, facendo eco anche ad alcune indicazioni della stessa NISO, avanza la proposta di estendere l'applicazione della OpenURL dall'ambito delle citazioni bibliografiche alla descrizione di tutti gli oggetti nominabili su web per cui un autore voglia emettere un link a risoluzione aperta in un qualunque documento html, e presenta il modello Bison-Futé, che si muove in territori contigui agli studi relativi al web semantico (in particolare quelli che riguardano l'uso di descrittori formali per annotare documenti non formalizzati). Invece che di OpenURL si parla di:
Praticamente, per emettere la OpenURL, oltre a formattare i metadati nel modo appropriato, è necessario che la risorsa origin sia ogni volta informata dell'apposito componente di reindirizzamento dell'utente, unica garanzia di context-sensitiveness (si può dire che deve implementare una risoluzione selettiva, cioè la capacità per un sistema di scegliere a quale risolutore indirizzarsi): la risorsa può ottenere questo scopo in vari modi, tra cui:
di modo che il cookiePusher possa reindirizzare l'utente alla risorsa desiderata, dopo aver messo sul client un cookie con l'indirizzo del server per servizi estesi, a quel punto disponibile per l'intera sessione.
Una volta che il cookiePusher è stato installato, la URL per connettersi a quella risorsa deve essere:
CookiePusher_URL?SFX_location=local_SFX&redirect=service_URL
laddove:
Di notevole interesse è il progetto di collaborazione con DOI, iniziativa nata nel contesto degli editori di riviste elettroniche, che hanno ideato un metodo di interconnessione tra gli articoli attraverso le citazioni: l'idea è di attribuire un codice identificativo, il Digital Object Identifier, ad ogni articolo e di registrare su server centrale, nel database CrossRef, per ognuno di essi:
Per ogni nuovo editore, basterebbe dunque includere una URL che punti al proxy DOI e passi come parametro il numero DOI, perché venga risolta nella URL dell'editore. Ma questo genera il "problema di Harvard o della copia appropriata", e d'altro canto non permette di aggiungere altri servizi.
La collaborazione con SFX ha condotto ad aggiungere al Proxy DOI la capacità di sapere se un certo utente ha accesso ad un componente di servizio SFX e in tal caso di operare un reindirizzamento a tale componente tramite una OpenURL che contenga l'identificatore DOI; si è trattato insomma di rendere il proxy DOI stesso OpenURL compliant, cioè capace di conoscere il componente di servizio dell'utente tramite cookiePusher e di emettere OpenURL. Si tratta dunque di un meccanismo potente ed economico, che permette di passare da un sistema di linking chiuso ad uno aperto con pochissimi investimenti, realizzato attraverso la convergenza di standard, prodotti e identificatori, che, pur nati in contesti diversi, interagiscono allo scopo di fornire all'utenza servizi sempre più evoluti.
Cinzia Bucchioni, Biblioteca di Anglistica - Universit� di Pisa, e-mail: bucchioni@angl.unipi.it
Note
* Questo articolo riprende il testo della relazione tenuta in occasione del Seminario "Open Archive per una comunicazione scientifica 'free'", organizzato dalla Biblioteca di Matematica, Informatica, Fisica dell'Universit� di Pisa, con il patrocinio AIB - Sezione Toscana e CNUR - Commissione Nazionale Universit� e Ricerca, Pisa, 12 giugno 2002.
[1] Tentando un confronto tra SFX Server e openResolver di UKOLN (per la cui comprensione è consigliabile una previa lettura completa del presente lavoro):
E' vero che la soluzione SFX proprietaria costringe a passare attraverso il fornitore per qualsiasi aggiustamento di tiro, implementazione di nuove sintassi, aggiunta di risorse completamente nuove o modifica di quelle esistenti. Ma d'altra parte fornisce un sistema di ampia repertoriazione delle risorse esistenti, in cui le soglie globali sono praticamente già implementate, e parametrizzato per una facile gestione delle soglie locali.
[2] Per una comprensione di queste note è necessario ricordare almeno che le URL sono sempre costituite da un indirizzo che punta ad un certo file su una certa macchina; nei casi più semplici tale file è una pagina web statica, che al click viene presentata; ma tale file può essere anche un programma che al click viene attivato: in tal caso la URL può essere più complessa, e all'indirizzo possono seguire una serie di parametri (separati da esso da un punto interrogativo), i quali non hanno significato per il web ma solo per il programma che li riceve e su di essi lavora.
[3] Le principali generalizzazioni, meglio comprensibili a fine discorso, sono state:
[4] Si noti che il componente di reindirizzamento, almeno nella soluzione SFX vera e propria, resta comunque in grado di arricchire i metadati della link-source traendoli dalla origin medesima o da altra fonte, lanciando cioè i vari script sourceParser definiti per risorsa.
[5] I sourceParser non fanno altro che implementare l'accesso alla risorsa origin utilizzando i protocolli eventualmente ammessi (Z39.50, HTTP etc.), ed arricchire i metadati ricevuti nella OpenURL; invero questo era il meccanismo ideato prima della OpenURL, e presuppone sourceParser per ogni risorsa e la conoscenza della origin; ma i metadati possono anche essere tratti da altra fonte, anzi questa è la direzione generalizzabile indicata dalla OpenURL: infatti quanto più vengono utilizzati identificatori di domini (namespace) globali dove andare a prendere metadati (invece che identificatori locali specifici per risorsa) tanto più i sourceParser sarebbero generalizzati (per dominio). Il cambiamento di prospettiva è evidenziato anche dal fatto che nello standard OpenURL il parametro origin è facoltativo, mentre nei primi esperimenti SFX la prima selezione di servizi possibili nel Colli si basa proprio sulla origin; è perciò stato necessario aggiungere al Colli una selezione per "qualsiasi origine" in relazione a tutti i target, per cui funzionano solo i filtri delle soglie.
[6] La OpenURL è un'evoluzione della concezione iniziale della SFX URL:
formato generale: target?serviceDesc&objectDesc
formato dettagliato: local_SFX?vendorID=<il_fornitore>&databaseID=<la_base>&objectDesc=<l'identificatore>
Link ai riferimenti bibliografici
![]()
![]()
![]()