![]()
![]()
![]()
![]()
![]()
![]()
La presente nota intende riprendere brevemente il discorso avviato ormai due anni fa su queste pagine a proposito delle tecnologie di context sensitive linking e del collegato processo di standardizzazione della OpenURL, individuata come strumento essenziale per superare un ambiente di link chiusi e proprietari (cioè ogni volta "contrattati" tra fornitori di contenuti o dati bibliografici) e realizzare una interconnessione tra contenuti elettronici, generalizzata e capace di tener conto del contesto di fruizione.
In questi anni il context sensitive linking è divenuto familiare ad un numero sempre maggiore di colleghi anche in Italia, soprattutto a seguito della significativa diffusione delle applicazioni SFX. Può dunque rivestire qualche interesse gettare uno sguardo avanti sull'evoluzione in corso per lo Standard di riferimento, per quanto di rilevanza non immediatamente applicativa.
La prima osservazione che si impone è che la versione 0.1 dello Standard ha avuto una fortuna implementativa ampia e rapida tra gli attori del mercato dell'informazione elettronica accademica [1], probabilmente proprio perché nata in contesto applicativo.
Il riferimento è agli ormai classici esperimenti congiunti Università di Gent - National Laboratory di Los Alamos [2], che hanno portato:
Solo per ricordare che cosa si intende per servizi estesi, ecco un esempio dei servizi desiderabili per una citazione bibliografica trovata in calce ad un articolo elettronico:

Questa nota intende lasciare da parte le problematiche relative alla realizzazione del server o componente di rete in grado di fornire tali servizi, per focalizzarsi sul processo di standardizzazione della OpenURL, ovvero lo strumento di linking funzionale a un tale server e a tali servizi.
La NISO, accettando la dettagliata specifica tecnica elaborata dal gruppo di progetto SFX come base di partenza (cioè come versione 0.1) per uno standard di più ampio respiro, ha avviato fin da subito una profonda riflessione sulle problematiche relative, in vista di una revisione diretta all'estensione e generalizzazione della OpenURL [4].
Nel corso del 2003 presso la NISO (AX Committee) è stata messa a punto una nuova versione (la 1.0) dello Standard, che è rimasta a disposizione come draf sul sito dell'Organizzazione dal gennaio al marzo 2004. Attualmente, conclusasi questa fase, il documento si trova nello stato "approvato, in attesa di pubblicazione" e uscirà come Standard ANSI/NISO Z39.88-200X.
E' dunque di questo documento, e della tecnologia in esso prefigurata, che qui si cercherà di dare un'idea.
Lo Standard si compone:
Da un punto di vista funzionale, c'è assoluta continuità tra le due versioni dello Standard: il punto fermo è la finalizzazione alla fornitura di servizi contestualizzati rispetto all'ambiente di fruizione. Da qui la necessità di interrompere il link, predefinito in un documento di partenza verso un documento target, per intercettarlo all'interno dell'ambiente dell'utente e re-dirigerlo; l'idea è quella di un link (l'OpenURL appunto) che invece che condurre ad una destinazione prefissata, impachetti l'informazione relativa all'elemento citato e la invii ad un "componente di servizio" (o server di linking), in grado di interpretarla di re-dirigere il link tenendo conto dell'ambiente di fruizione.
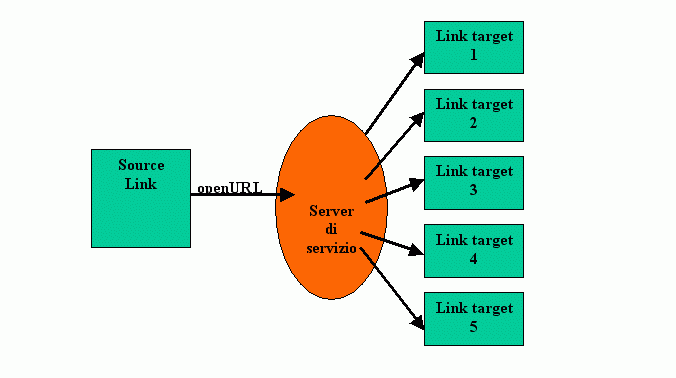
Traducendo dall'abstract che apre lo Standard:
"Lo Standard OpenURL standardizza la costruzione di pacchetti di informazione e dei metodi per trasportarli sulla rete. Destinatari di questi pacchetti si intendono dei componenti di rete per servizi contestualizzati. Per rendere possibili questi servizi ogni pacchetto descrive, oltre la risorsa per cui si desiderano i servizi, anche il contesto di rete in cui tale risorsa è citata".
La nuova versione dello Standard attua un'estensione della precedente sotto i seguenti profili:
Partendo dall'esame della OpenURL "primo tipo" (cioè quella definita dalla versione 0.1 dello standard), di cui si riporta un esempio:
http://sfx1.exlibris-usa.com/demo
?sid=ebsco:medline&aulast=Moll&auinit=JR&date= 2000-11-03&stitle=J%20Biol%20Chem&volume=275&issue=44&spage=34826il processo di generalizzazione è giunto a riconoscervi la descrizione di tre entità, e cioè:
un server di servizi (BaseUrl)
La nuova versione dello Standard definisce e riordina questi elementi come:
e, anche sulla base di analisi delle scelte fatte nelle implementazioni concrete, vi aggiunge altre tre entità contestuali che possono risultare necessarie per pienamente definire una situazione informativa:
Lo Standard parla dunque di un costrutto informativo, il ContextObject, il quale contiene la descrizione di sei entità:
|
referent |
rft |
entità citata su web per cui si chiedono servizi |
(1, obbligatorio) |
|
------- entità contestuali: |
|||
|
resolver |
res |
link server |
(0 o 1) |
|
referrer |
rfr |
piattaforma, servizio che invia OpenURL |
(0 o 1) |
|
referring entity |
ref |
risorsa che cita il referent |
(0 o 1) |
|
requester |
req |
agente che chiede i servizi (lato utente) |
(da 0 a molti) |
|
service-type |
svc |
il tipo di servizio richiesto |
(da 0 a molti) |
Traducendo ancora dall'abstract dello Standard [5]:
"Un ContextObject è un costrutto informativo che contiene:
Lo Standard specifica come costruire le rappresentazioni dei ContextObject, che sono i pacchetti informativi trasportabili sulla rete che facilitano la fornitura di servizi context-sensitive."
Vale la pena di riportare anche la "situazione di esempio" utilizzata nello Standard [6]:
Jane Doe, studentessa all'Università di Caltech, sta leggendo il seguente articolo elettronico, della collezione ScienceDirect dell'editore Elsevier:
McArthur, James G. et al. Chimera: A Superior Antiproliferative for the Prevention of Neointimal Hyperplasia. Molecular Therapy. fasc.1, vol.3(2001), p. 8-13. <doi:10.1006/mthe.2000.0239>
Nella lista bibliografica in calce all'articolo, la studentessa trova citato quest'altro articolo:
Bergelson, J. 1997. Isolation of a common receptor for coxsackie B viruses and adenoviruses 2 and 5. Science. (275) 1320-1323. <doi:10.1126/science.275.5304.1320> <pmid:9036860>
Per questa citazione il fornitore mette a disposizione una OpenURL, che può condurre Jane a vari servizi disponibili nella sua Università per tale articolo (full text, impact factor, altri articoli dello stesso autore). Le entità del ContextObject di tale OpenURL sono così individuate:
All'interno del ContextObject, ogni entità viene descritta da un descrittore. I descrittori possono essere di diverso tipo:
_id
: descrittore identificatore_val: descrittore "per valore" in metadati => informazione esplicita
citazione di uno schema (tramite URI)
+ descrizione secondo quello schema
_ref: descrittore "per citazione" in metadati =>informazione implicita
citazione di uno schema (tramite URI)
+ puntatore ad una descrizione dell'entità secondo quello schema (tramite URI)
_dat: descrittore "privato" cioè non registrato nel registro
Ogni descrittore può essere codificato in modi diversi ed utilizzare identificatori o metadati diversi; inoltre, all'interno del costrutto informativo ContextObject, può variare il modo di esprimere e combinare i descrittori.
Ogni tecnica di codifica costituisce un "formato"; esistono dunque:
Sono inoltre utilizzabili diverse codifiche di carattere, diversi metodi di trasposto sulla rete, etc.
Il nuovo Standard è dunque un framework, cioè una cornice generale (non un protocollo), che prevede:
Partendo così da funzionalità analoghe a quelle previste nella prima versione, si giunge ad una struttura molto più complessa; si veda un esempio parziale di costrutto informativo espresso secondo la nuova versione dello Standard:
|
http://example.org/myResolver?url_ver=z39.88-2004 |
(dalle prime righe si evince che si tratta di una inline OpenURL) |
|
&url_ctx_fmt=info:ofi/fmt:kev:mtx:ctx |
(formato di ContextObject) |
|
&rft_val_fmt=info:ofi/fmt:kev:mtx:journal |
(formato di metadati: referent per val) |
|
&rfr_id=info:sid/myid.com:mydb |
(referrer per identificatore) |
|
&rft_id=info:doi/10.1126/science.275.5304.1320 |
(referent per identificatore) |
|
&rft_id=info:pmid/9036860 |
(referent per identificatore) |
|
&rft.genre=article |
|
|
&rft.atitle=Isolation of a common receptor for coxsackie B |
|
|
&rft.title=Science |
|
|
&rft.aulast=Bergelson |
|
|
&rft.auinit=J |
|
|
&rft.date=1997 |
In questo costrutto è facile riconoscere i dati della OpenURL "primo tipo".
La novità sostanziale è che esso va interpretato non direttamente sulla base dello Standard, ma sulla base dello specifico formato di ContextObject, registrato nel registro come:
e qui citato alla riga:
Solo nell'ambito di tale formato di ContextObject acquisiscono significato le righe:
|
&rfr_id=info:sid/myid.com:mydb |
(identificatore usato per il referrer) |
|
&rft_id=info:doi/10.1126/science.275.5304.1320 |
(identificatore usato per il referent) |
|
&rft_val_fmt=info:ofi/fmt:kev:mtx:journal |
(dichiarazione di formato di metadati) |
Quest'ultima riga cita il formato di metadati registrato come info:ofi/fmt:kev:mtx:journal, e precisa che qui sarà usato esplicitamente (by-value) per descrivere il referent; nell'ambito di questo formato di metadati, acquisiscono significato le righe seguenti del tipo:
Le prime righe del costrutto esprimono dati relativi al metodo di trasporto utilizzato in questo caso (Inline OpenURL su HTTP) anch'esso registrato come info:ofi/tsp:http:openurl-inline.
Fondamentale diventa quindi il Registro: in esso devono essere registrati tutti gli elementi poi utilizzati, nonché tutte le scelte di rappresentazione compiute a monte degli elementi direttamente utilizzati. Ad ogni elemento registrato, viene assegnato un identificatore di registro.
Al registro è dedicata tutta la seconda parte dello Standard, che specifica:
Relativamente al primo punto, si riconoscono otto classi di elementi soggetti a registrazione, come si è già osservato non tutti da utilizzarsi nei costrutti ma alcuni necessari per costruire altri elementi.
Relativamente al secondo punto, inserire un elemento nel registro significa assegnargli un identificatore univoco composto secondo una ben precisa sintassi, il quale, oltre a permetterne la citazione inequivoca, è collegato ad una descrizione Dublin Core e ad una documentazione completa; traducendo dallo Standard [7]:
"Il metodo per accedere ai singoli elementi del Registry è il seguente:
(nella URI sottoriportata, la parte in grassetto va sostituita con l'identificatore di registro unico per l'elemento)
� metadati Dublin Core che danno una descrizione generale dell'elemento si trovano a:
- <http://www.OpenURL.info/registry/dc/registry-identifier> (accesso da un Web browser)
- <http://www.OpenURL.info/registry/docs/dc/registry-identifier> (accesso diretto)
� l'effettiva definizione di ogni elemento del Registry [...] è accessibile alla URI contenuta nel campo
dc:identifier ; tale definizione è anche accessibile direttamente a:<http://www.openurl.info/registry/docs/registry-identifier> ".
Attenzione dunque a non fare confusione tra la metodologia di costruzione degli identificatori di registro, e l'effettivo significato di ogni elemento registrato e l'uso che ne viene fatto nei costrutti informativi.
Tornando alle otto classi di elementi soggetti a registrazione, se ne dà di seguito l'elenco, riportando esempi di elementi già inseriti nel registro, identificati mediante l'identificatore assegnato nel registro stesso:
|
1. Namespaces |
|
|
info:ofi/nam:urn:ISBN |
(identificatori da usare nei descrittori) |
|
info:ofi/nam:mailto |
|
|
info:ofi/nam:info:doi |
|
|
info:ofi/res |
(identificatori da usare nel registro) |
|
info:ofi/rfr |
|
|
info:ofi/rfe |
|
|
2. Codifiche per i caratteri (UTF8, ISO-8859-1 etc.) |
|
|
info:ofi:enc:UTF-8 |
(default) |
|
3. Rappresentazioni fisiche (KEV, XML) |
|
|
info:ofi/fmt:kev |
(rappresentazione che utilizza coppie nome=valore) |
|
info:ofi/fmt:xml |
(rappresentazione che utilizza XML) |
|
4. Linguaggi formalizzati (costruiti sulla base del precedente 3) |
|
|
info:ofi/fmt:kev:mtx |
(coppie nome=valore descritte in una matrice qui definita) |
|
info:ofi/fmt:xml:xsd |
(costrutti in XML espressi secondo il W3C XML Schema) |
|
5. Formati di ContextObject (costruiti sulla base di 3 e 4, ed effettivamente utilizzati nei costrutti OpenURL) |
|
|
info:ofi/fmt:kev:mtx:ctx |
(gli elementi effettivamente utilizzati per il ContexObject, espressi in una matrice di coppie nome-valore) |
|
info:ofi/fmt:xml:xsd:ctx |
(gli elementi effettivam. utilizzati per il ContexObject, espressi in uno schema XML) |
|
6. Formati di metadati (costruiti sulla base di 3 e 4, effettiv. utilizzati nei costrutti OpenURL; registraz.opzionale) |
|
|
info:ofi/fmt:kev:mtx:book |
(i metadati necessari per una descrizione di libro, espressi in una matrice di coppie nome-valore) |
|
info:ofi/fmt:xml:xsd:marc21 |
|
|
7. Metodi di trasporto: protocollo di rete e metodo d'impiego |
|
|
info:ofi/tsf:http |
|
|
8. Profili applicativi per comunità |
|
|
info:ofi/pro:dc |
Traducendo ancora dallo Standard [8] (le interpolazioni fra quadre sono di chi scrive):
"Il Registro OpenURL contiene:
1. l'informazione strutturata necessaria per creare rappresentazioni standardizzate di ContextObjects [elementi da 3 a 6];
2. i metodi standardizzati per trasportare queste rappresentazioni sulla rete [elemento 7];
3. i profili di settore (Community Profiles) dove una comunità concorda su specifiche rappresentazioni di ContextObject e metodi di trasporto [elemento 8].
[Si noti che gli elementi 1 e 2 sono trasversali alla triplice distinzione qui proposta].
Attraverso la registrazione di nuovi componenti, il Framework OpenURL può essere adattato ed esteso per soddisfare nuovi requisiti."
Per finire, qualche commento al contenuto del registro.
I formati
I formati, sia di metadati, sia di ContextObject, sono gli elementi principali che si trovano espressi nei costrutti informativi. Come si ricava da quanto detto sopra, i formati sono espressi da una tripla, cioè sono definiti da tre elementi:
Perciò la registrazione dei formati è possibile solo previa registrazione delle "rappresentazioni fisiche" e dei "linguaggi formalizzati" (elementi che non compaiono mai in quanto tali in un ContextObject).
In questa fase di avvio, il registro già contiene concretamente due "rappresentazione fisiche":
e due "linguaggio formalizzati" in cui rappresentarli:
Con questi elementi, vengono costruiti due formati di ContextObject e vari formati di metadati.
I namespace
I namespace [9] sono una classe di supporto alla gestione del registro stesso, in quanto includono gli identificatori di registro utilizzati. Ma comprendono anche tutti gli identificatori utilizzabili direttamente nei ContextObject, cioè i citati "descrittori identificatori" (le cui modalità di utilizzo e di espressione sono peraltro definite in ogni formato di ContextObject). Traducendo dallo Standard:
"Sono Namespaces validi [per la identificazione di entità] tutti quelli definiti da uno schema URI registrato dalla IANA, ivi inclusi gli identificatori URN registrati. Essi sono disponibili a:
� IANA URI Schemes registry: <http://www.iana.org/assignments/uri-schemes>
� IANA URN Namespace Identifiers Registry: <http://www.iana.org/assignments/urn-namespaces>".
Per una gestione coerente con l'infrastruttura della rete, è stato introdotto uno specifico schema URI, proprio per la gestione di questo registro; traducendo dallo Standard [10]:
"Nel giugno 2003, una rappresentanza della NISO, il Committee AX, il IETF, e il W3C si sono incontrati per discutere l'identificazione delle risorse nel Framework OpenURL e l'accordo è stato di procedere alla registrazione di un nuovo schema URI di livello superiore. Il primo Internet-Draft per questo "info" URI scheme è stato pubblicato nel settembre 2003, e una sua revisione a dicembre. Questo draft e ogni successiva versione sarà mantenuta al sito <http://info-uri.info/>. Attualmente l"info" URI scheme è in attesa dell'approvazione del IESG per poter essere pubblicato come "informational RFC".
Insomma, la ragione per cui, nel ContecxtObject sopra citato, si può utilizzare:
I metodi di trasporto
I metodi di trasporto sono anch'essi direttamente implicati nei costrutti informativi. Il registro comprende per ora sei metodi registrati, che sono in effetti tre metodi replicati secondo il protocollo HTTP e HTTPS. In tutti i casi sono presenti alcuni dati essenziali, quali la versione dello Standard e il formato di ContextObject.
La distinzione è essenzialmente tra il trasporto dei dati effettivi (By-Value e Inline OpenURL) e il trasporto del solo "indirizzo" dei dati (By-Reference OpenURL); mentre tra la Inline e la By-Value la distinzione è essenzialmente di codifica dei dati, restando la prima più aderente alla vecchia versione dello Standard.
By-Reference OpenURL: la rappresentazione fisica del ContextObject viene solo citata attraverso una URI che rimanda alla sua locazione di rete, come valore della chiave 'url_ctx_ref'.
Ecco l'esempio dello Standard, per una By-Reference OpenURL che trasporta, usando HTTP GET, l'indirizzo di rete di un KEV ContextObject ad un OpenURL Resolver con indirizzo: http://www.example.net/menu:
http://www.example.net/menu?
url_ver = Z39.88-2004 &
url_tim = 2002-08-16T17:23:45Z &
url_ctx_fmt = info:ofi/fmt:kev:mtx:ctx &
url_ctx_ref = http://www.example.org/temp/12587.txt
http://www.example.net/menu?url_ver=Z39.88-2004&url_tim=2002-08-16T17%3A23%3A45Z&url_ctx_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Actx&url_ctx_ref=http%3A%2F%2Fwww.example.org%2Ftemp%2F12587.txt
Inline OpenURL: la rappresentazione fisica del ContextObject viene direttamente inserita come sequenza di molteplici coppie chiave=valore.
Ecco l'esempio dello Standard, per una Inline OpenURL che trasporta, usando HTTP GET, la rappresentazione di un KEV ContextObject ad un OpenURL Resolver with con indirizzo: http://www.example.net/menu:
http://www.example.net/menu?
url_ver = Z39.88-2004 &
url_tim = 2002-03-20T08:55:12Z &
url_ctx_fmt = info:ofi/fmt:kev:mtx:ctx
& rft_id = info:doi/10.1126/science.275.5304.1320
& rft_id = info:pmid/9036860
& rft_val_fmt = info:ofi/fmt:kev:mtx:journal
& rft.title = Science
& rft.atitle = Isolation of a common receptor for coxsackie B viruses and adenoviruses 2 and 5
& rft.aulast = Bergelson
& rft.auinit = J
& rft.date = 1997
& rft.volume = 275
& rft.spage = 1320
& rft.epage = 1323
& rfe_id = info:doi/10.1006/mthe.2000.0239
& rfr_id = info:sid/elsevier.com:ScienceDirect
& req_id = mailto:jane.doe@caltech.edu
& ctx_tim = 2002-03-20T08:55:12Z
& ctx_enc = info:ofi/enc:UTF-8
http://www.example.net/menu?url_ver=Z39.88-2004&url_tim=2002-03-20T08%3A55%3A12Z&url_ctx_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Actx&rft_id=info%3Adoi%2F10.1126%2Fscience.275.5304 .1320&rft_id=info%3Apmid%2F9036860&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal&rft.title=Science&rft.atitle=I solation%20of%20a%20common%20receptor%20for%20coxsackie%20%20B%20viruses%20and%20adenoviruses%202%20and%20%205&rft.a ulast=Bergelson&rft.auinit=J&rft.date=1997&rft.volume=275&rft.spage=1320&rft.epage=1323&rfe_id=info%3Adoi%2F10.1006% 2Fmthe.2000.0239&rfr_id=info%3Asid%2Felsevier.com%3AScienceDirect&req_id=mailto%3Ajane.doe%40caltech.edu&ctx_tim=200 2-03-20T08%3A55%3A12Z&ctx_enc=info%3Aofi%2Fenc%3AUTF-8
By-Value OpenURL: la rappresentazione fisica del ContextObject viene direttamente inserita, come valore dell'unica chiave 'url_ctx_val' (che comprende dunque tutto il ContextObject). Questa modalità, che implica una doppia codifica dei valori delle chiavi, è opportuna per trasportare ContextObject espressi in XML.
Ecco l'esempio dello Standard, per una By-Value OpenURL che trasporta, usando HTTP GET, una rappresentazione di un semplice KEV ContextObject ad un OpenURL Resolver con indirizzo: http://www.example.net/menu:
http://www.example.net/menu?
url_ver = Z39.88-2004 &
url_tim = 2002-08-16T17:23:45Z &
url_ctx_fmt = info:ofi/fmt:kev:mtx:ctx &
url_ctx_val = rft_id=info:doi/10.1126/science.275.5304.1320
url_ver=Z39.88-2004&url_tim=2002-08-16T17%3A23%3A45Z&url_ctx_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Actx&url_ctx_val=rft_id%3Dinfo%253A doi%252F10.1126%252Fscience.275.5304.1320
Dove si noti la doppia codificazione come URL dei Valori trasportati: una codificazione richiesta dal formato KEV del ContextObject, la seconda dalla sintassi della URI.
Cinzia Bucchioni, Centro Bibliotecario LM2 - Universit� di Pisa, e-mail: bucchioni@angl.unipi.it
[1] Il dato è molto rilevante, anche se rimane l'impressione che il funzionamento delle applicazioni disponibili, quanto più riesca soddisfacente tanto più sia pesantemente basato su soluzioni ad hoc, forse proprio perché il perseguimento di un server di servizio efficace ha preceduto il processo di standardizzazione; e che a volte l'adeguamento allo standard sia attuato in maniera minimale. A questo proposito sarebbe interessante verificare quanti dei prodotti OpenURL compliant utilizzino l'identificatore "privato", sfuggendo così al controllo dello standard; o ancora quanti dei servizi effettivamente disponibili siano resi possibili non tanto dai dati passati con la OpenURL ma piuttosto dal ri-accesso da parte del server di linking alla risorsa di partenza per arricchire i dati, processo questo che si attua attraverso sourceParser specifici per risorsa.
[2] Cinzia Bucchioni, SFX e OpenURL: gli esperimenti del team di Van de Sompel in "Bibliotime", anno V, numero 2 (luglio 2002), <http://www.spbo.unibo.it/bibliotime/num-v-2/bucchion.htm>.
[3] Il server prototipale messo a punto durante la sperimentazione, è stato poi ceduto all'azienda ExLibris ed è attualmente commercializzato col nome SFX.
[4] La direzione della revisione della NISO viene tracciata già nell'articolo di Van de Sompel, Herbert, Oren Beit-Arie, Generalizing the OpenURL Framework beyond References to Scholarly Works: The Bison-Futé Model in: "D-Lib Magazine", volume 7, numero 7/8 (July/August 2001), <http://mirrored.ukoln.ac.uk/lis-journals/dlib/dlib/dlib/july01/vandesompel/07vandesompel.html>. Traduzione italiana sul sito della CNUR, <https://www.aib.it/aib/commiss/cnur/trsomp5.htm3>.
[5] The OpenURL Framework for Context-Sensitive Services. Part 1: ContextObject and Transport Mechanisms, p. i, <http://library.caltech.edu/openurl/StandardDocuments/Z39_88_Pt1_ballot final.pdf>.
[6] The OpenURL Framework for Context-Sensitive Services. Part 1: ContextObject and Transport Mechanisms, p. 6.
[7] The OpenURL Framework for Context-Sensitive Services. Part 2: Initial Registry Content, p. 1
[8] The OpenURL Framework for Context-Sensitive Services. Part 1: ContextObject and Transport Mechanisms, p. i.
[9] Per chiarire ai non addetti ai lavori il significato, ampio perché trasversale a parecchi contesti, di namespace, può essere un utile punto di partenza la Wikipedia:
<http://en.wikipedia.org/wiki/Uniform_Resource_Identifier>
<http://en.wikipedia.org/wiki/Namespace_%28programming%29>
<http://en.wikipedia.org/wiki/XML>.
[10] The OpenURL Framework for Context-Sensitive Services. Part 1: ContextObject and Transport Mechanisms, p. 3.
![]()
![]()
![]()