![]()
![]()
![]()
![]()
![]()
![]()
The purpose is to illustrate how the ISSN has been used in a variety of library purposes, with reference to activity spanning times before and after the arrival of the Web: MODELS workshops, the CASA Project, SUNCAT, the Keepers Registry and KB+. A number of threads intertwine in this story about uses of the ISSN, the international standard serials number that serves as the globally accepted identifier for journals and other serials. Within the library context the interest is for resource discovery, links to electronic tables of contents and full text, as well as for bibliographic control and decisions about buying and cancelling subscriptions. The priority task for librarians changes in emphasis but is essentially that of ensuring that researchers, students and their teachers can have ease and continuing access to online scholarly resources. For that, the ISSN delivers advantage as an internationally accepted dumb number.
This is based upon a presentation made at the 2012 ACNP-NILDE Conference held in Bari, 22/23 May 2012. [1] There is large overlap in content in what is written here and what was shown and said.
The ISSN (International Standard Serial Number) derives from ISO 3297 and is an eight-digit number which identifies periodical publications, including electronic serials. Unlike many other identifiers, the ISSN is an identifier for the issue of content. The correspondence between an ISSN and a given title or point of issuance - is intended to be unique, but the numbers in an ISSN do not contain any information referring to the origin or contents of the publication. The ISSN Manual has recently been updated. [2]
This explains the reference to the phrase 'dumb number'. A number is referred to as 'dumb' if the numerical value conveys no meaning other than to act as a reference to what appears in a list or database. The ISSN is such a number with respect to what appears in the ISSN Register as the record for a given serial title.
A number of threads intertwine in this story about uses of the ISSN, the international standard serials number that serves as the globally accepted identifier for journals and other serials.
Context
For libraries and scholarly communication, perhaps the most significant of these threads is the shift from print to digital that has been taking place over the past thirty years or so. A related thread concerns re-examination of how to share access to authoritative metadata about serials at Web-scale, with associated thoughts about the changing role for nationally and regionally controlled facilities such as union catalogues of serials. This connects to a third thread, the search by librarians and policy makers for the appropriate institutional and national form of response to the 'web-scale' developments that are controlled by others, often multinational corporations that have gained or would seek to gain control over key bibliographic resources, that seem beyond control or influence by the library community. Underpinning this tangle is a shared focus by libraries upon their essential task: to ensure both ease and continuity of access to scholarly content for researchers, students and their teachers now and into the future.
Use of identifiers is crucial. Within the library context the interest is for resource discovery, links to electronic tables of contents and full text, as well as for bibliographic control and decisions about buying and cancelling subscriptions. Within the publishing world the interest is for in-house tracking and management, rights transactions, copyright management and economies of electronic referencing. Sometimes these interests coincide; sometimes not.
Recognition of the importance of identifiers and authority files predates today's world of the World Wide Web, wifi/mobile devices, and the replacement of mediation by the librarian and library systems by web-scale multi-nationals such as Google (Scholar), Amazon and the like.
Cataloguing and other metadata
Reference was made to the period of the past thirty years or so: that is, from around 1980. To some extent, the remark is made because it marks personal recognition of the significance of metadata and cataloguing of research data files. This was first as a survey statistician working as producer of a flow of digital content from periodic surveys and also as provider into the Scottish Education Data Archive of the resultant datasets for others to analyse. Then it was managing Edinburgh University Data Library in 1984, established to meet the needs of the University's researchers and students. That meant working out how to apply the various verbs and practices of the 'library' word to data. It also meant learning how to seek out research data produced by others, typically by government agencies and other researchers but also by commercial agencies.
More generally in the pre-Web era of the Internet, this was when Sue Dodd published her interpretative manual [3] to assist data librarians understand the significance of Chapter 9 of AACR2 on 'Machine-Readable Data Files', published in 1978, renamed 'Computer Files' when the revision of AACR2 Chapter 9 was published in 1988. There was attempt to gain consensus in the UK for a 'computer files cataloguing guide' [4].
Of course, for serials librarians in the UK, attention was on the evolution of AACR2 Chapter 12, with its attempt to harmonize across three organizations with rules for metadata about serials: AACR2, ISBD (CR) and ISSN. The AACR2 (2002) Chapter 12 on Serials was renamed 'Continuing Resources', then 'Electronic Resources'. With the phrase 'integrating resources', firmly in the era of the Web, there was distinction serial content that was issued in parts (e.g. e-journals) and content on the Web that changes over time.
Words, Numbers, Pictures, Sounds: All will be digital and access from afar
Bit by bit there was more and more, the text of e-journal content coming later after numeric data files, and now pervasive multimedia. Five unevenly spaced way-markers are used here to provide indication of the direction of travel, as digital content emerges as the mainstream format:
The early Web enabled easier and more predictable rendering of user interfaces (HTML) for presentation of digital content and easier means of access to digital information (HTTP). It built upon but also radically transformed the uses being made by the scholarly community of the Internet that had already enabled and demonstrated the telematic advantages of email, remote log-on and file transfer. The Web has had global significance beyond the walls of universities, libraries and scholarly communication, and it may be worth noting that only with the Web did interaction between libraries and publishers really start to change.
The emergence of distributed systems
In the initial phase this mostly meant digital access to information about an object that was physically located somewhere. For a while the term 'database' within libraries was interpreted and limited to the abstract and indexing (A&I) databases used for the discovery of bibliographic references. The actual contents of journals and other serials the full text - remained mostly print and on-shelf.
As what was digital and online was becoming recognised as indicative as the 'future present', there was shift in focus to links from metadata for discovery to the online full text. The value of a dumb number like the ISSN began to receive renewed attention, as 'actionable metadata', acting as the linchpin for interoperability across systems, as illustrated in Figure 1 below.
Figure 1: The ISSN as linchpin in the information chain

The graphic illustrates four demand-side verbs which were adapted from the MODELS workshops <ref>: Discover -> Locate -> Request -> Access (Deliver). These (MOving to Distributed Environments for Library Services) workshops formed part of the Electronic Libraries (eLib) Programme. [5]
The workshops were intended to assist development of an applications framework within which to manage the rapidly multiplying range of distributed heterogeneous information resources and services being offered to libraries and their users. They provided a forum within which the UK library and information communities explored shared concerns, address design and implementation issues, initiate concerted actions, and work towards a shared view of preferred systems and architectural solutions.
The summary of one of the early workshops, on Identifiers, makes interesting reading. [6] It notes the suggestion that the International Standard Work Code (ISWC), which identified the musical composition itself, rather than the recorded or printed expression of the work, might be extended to cover literature and the visual arts as well. This would seem the genesis of FRBR. Similarly, the suggestion that the Compositeur, Auteur, Editeur (CAE) number, which identified creators and publishers, could be extended and renamed the Interested Party (IP) number, would seem to foresee both the ISNI and much else.
Three leading actors at those workshops provide the summary of the workshop series and subsequent actions. [7] This includes reference to the role that EDINA was seeking to play.
How EDINA came about
In 1996 EDINA [8] the Data Library at the University of Edinburgh was designated as a (UK) national data centre by JISC [9] acting on behalf of the government funding bodies for higher education. EDINA was one of three JISC national data centres selected by competitive tender to serve the needs of all researchers and students in the UK. One was BIDS (at the University of Bath) which hosted and provided access to the ISI database (now Web of Science). The other was Midas (now Mimas) at the University of Manchester.
EDINA began to host a wide variety of abstract and indexing databases, including Art Abstracts, BIOSIS Previews, Compendex, EconLit, INSPEC, MLA, PAIS. There was already experience in designing and operating SALSER, the union catalogue of serials for 60 libraries across Scotland, arguably the first national union catalogues on the Web, both early use of HTTP and also use of Z39.50 for federated searching.
The CASA Project
That was the context within which EDINA engaged in the CASA project, led by CIB at the University of Bologna, as a partner alongside the ISSN International Centre (ISSN-IC). [10] Entitled 'Co-operative Archive on Serials & Articles', CASA was funded under the EU 4th Framework: Telematics for Libraries Programme. [11] Many positive professional and personal relationships were forged in that project which ran from 1997 through to December 2000. [12]
In the 2nd phase of the project, from 1998, the focus of project was switching from the initial notion of a centralised 'Archive' to distributed 'Activity', hence new 'descriptive title': CASA: 'Co-operative Activity on Serials & Articles', although the 'title proper' probably remained unchanged. The overall aim was to assist users & providers of services on serials & articles through identifiers & supporting authority files, including those extant for serials (ISSN) and what were then seen as emerging for articles (SICI & DOI). Among the project objectives and 'deliverables' was a 'research and development' (R&D) activity which we called the Serials Services Directory and early prototyping to combine XML and RDF with the (legacy) Z39.50. Written up in Bollini, Burnhill & Di Cocco, [13] this drew upon the computer science expertise of the first author and the mix of experience and insight from the second and third, and is captured in the following schematic for a Serial Services Directory [14], shown as Figure 2.
Figure 2: Serials Services Directory
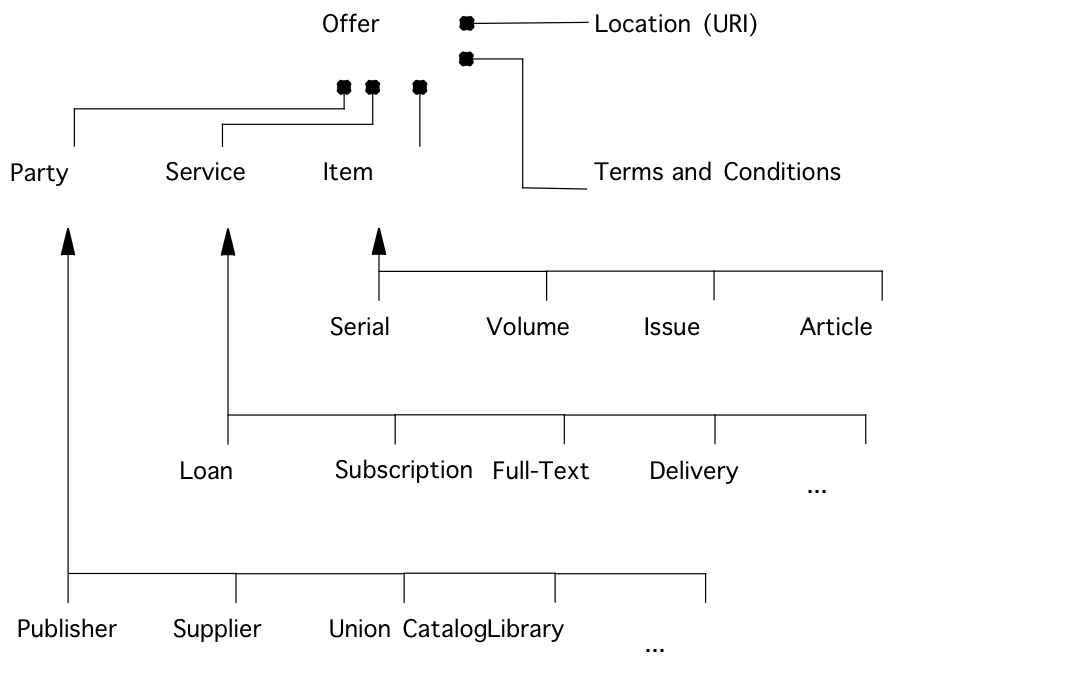
As indicated by the services listed, the emphasis then was on assisting the searcher with visits to the libraries held the full text on-shelf, inter-library loan schemes and envisioning the beginnings of access to the full text online and of electronic document delivery.
Early attempt at Join-up in the UK
In late 1990s, EDINA gained further knowledge of distributed architecture and Z39.50 in the JISC-funded JOIN-UP Programme which brought together four projects that were looking at federated searching by Z39.50: for 'discovery by cross searching A&I databases': use of electronic tables of contents; a general locate facility; supply of online full text of electronic from the British Library and/or from library consortia. These never became parts of any integrated whole but the summary from a workshop provides indication of what was hoped. [15]
The British Library proceeded to make its Table of Contents available as the zetoc service developed and hosted at EDINA's sister organization, Mimas, and EDINA produced two software systems, GetRef and GetCopy. GetRef cross-searched across the subscribed A&I databases for any given library and the GetCopy as a locate facility that used the OpenURL protocol [16] to find the 'appropriate copy' for a given bibliographic reference. This enabled requests for online electronic content to be included within the URL across HTTP to connect with offers of service for a, a low-cost OpenURL resolver as became prevalent within the commercial sector. GetRef also included an approach for 'request' as the OpenURL can also includes authorisation information about the requester.
An important but low-cost product of that JOIN-UP activity still continues as a JISC-funded national service, the OpenURL Router [17] which tackled what could be regarded as the 'appropriate resolver' problem, re-directing requests to the OpenURL knowledgebase to which the library of a searcher subscribes.
Some (unintended) Consequences of The Web/Internet
Libraries are no longer are seen as the place to take physical custody of key content required by researchers. The essentials of supply chain have changed: what is on offer is a license for access and not sale for delivery of goods (content) - what is bought by a library a mixture of sale of entitlement and an access service. Access is provided for what is online remotely, not on-shelf locally. This prompts the thought that role of libraries as trusted keepers of information and culture has been disrupted. Priority needs to be given to securing assurance about continuity of access: of all content for future generations; of the back copies, especially if there is economic need to cancellation of the licence.
The priority task for librarians and academic support, locally and 'at the network-level', is to ensure that researchers, students and their teachers have ease and continuing access to online scholarly resources. The role of libraries can be re-stated graphically, as in Figure 3.
Figure 3: The central task for librarians
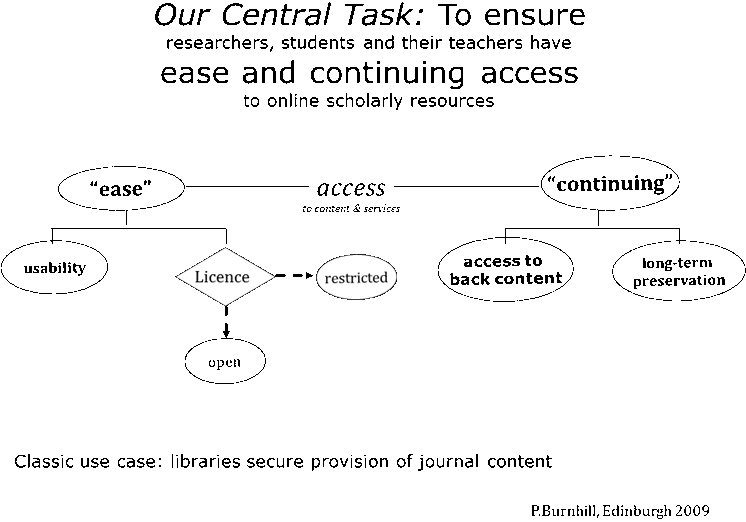
Article-length work published in e-journals provides an ideal example: available in digital format, online under some form of licence - either by subscription or to be observed by the user (as is the case with Creative Commons licensing).
Ease of access is regarded here as to do with usability and with licence conditions and management of authorisation. Continuity of access is regarded here as including both long-term preservation and continuing access to back copy, regardless of current subscription status.
There is also reminder that we all seek ease of access to back content as well as current content, for what is online in digital format as well as what has long been on-shelf as bound paper and is coming to be available because of digitisation. We seek ease and continuity of access to content on the digital shelf. The challenge is to reason what are the cost-effective points of service for that content, supported by forms of infrastructure - such as authoritative network-level registries - above the level of the institution, potentially of international as well as national character. The assignment of identifiers for digitised content becomes a priority.
Following a feasibility study for a national union catalogue in 2001 and a scoping study for a serials union catalogue in 2002, the decision was made to commission the design and build of such a facility [18]. So began a multi-phase activity to build SUNCAT that was to have three principal functions:
Phase 1 started in 2003, led by EDINA is partnership with Ex Libris, and going from investigation and prototype, using ALEPH 500, with catalogue data from six of the largest research libraries in the UK, including Oxford and Cambridge, and then later the British Library, with regular updates from the CONSER database and from the ISSN Register. As with any union catalogue, matching of records is both critical and challenging. The ISSN was important although only a minority of serials in any one of these six libraries has an ISSN in the record, largely because these were older serials for which no assignment had ever taken place. We had to fall back upon ingenuity but also the frailty of matching text in the basic fields of title, publisher, place of publication etc. By the end of Phase 1 we had extended coverage to 22 research and university libraries across the UK for formal launch in 2005.
Today SUNCAT holds the serial records of all the major research libraries in the UK with a database in excess of 5m records. It covers 85 institutions including all 32 members of RLUK (Research Libraries UK) and most of the members of the 1994 Group, as well as the three national libraries and a growing number of specialist libraries for major research institutes and cultural organisations. About ten (10) new libraries are added annually. There is now update from the Directory of Open Access Journals (DOAJ).
As noted above, primary purpose of SUNCAT [19] is as a finding aid for researchers, students and librarians, indicating who holds what serial. With recent addition of mobile phone App, the geography of 'who holds what where' is more obvious. The range of services for researchers and students has also broadened: access to the full text via use of Table of Contents and the UK OpenURL Router and the UK Access Management Federation (Shibboleth) is now possible, although this is not yet as obvious on the SUNCAT website as it should be. And use of the ISSN, is required, as discussed above, to move along that chain of discovery, location (of service), request (by privilege of membership) and then online access,.
SUNCAT continues a source of shared cataloguing so that all institutional libraries can upgrade their local OPACs including addition of ISSN, via an API. Use of this download facility increased dramatically during 2011/12, enabling report to JISC of impressive cost effectiveness with, at £0.15 per search & download. This was largely due to the provision of services to the 29 libraries in UK Research Reserve (UKRR): to support selection of candidate titles for which the printed volumes can be removed from shelves into a shared store for print archiving, without the need to check manually the holdings of the other 28 libraries. Here there is a mix of titles with ISSN those without take much longer to process. This is not the last time to assert that 'if it is worth archiving it should have an identifier'. And print archiving exercises should represent opportunity for retrospective assignment of ISSN to older print serials.
In 2008, EDINA and the ISSN-IC became partners in a JISC-funded project to Pilot an E-journal Preservation Registry Service (PEPRS). The ISSN Register is at the heart of the design of this registry in order to match, record and then display the archiving activity of various organizations that are taking long time care of electronic serials. This is illustrated in Figure 4, taken from the reference paper for this project [20] published in Serials, the journal of the UKSG.
Figure 4: Abstract Data Model for E-Journal Preservation Registry Service
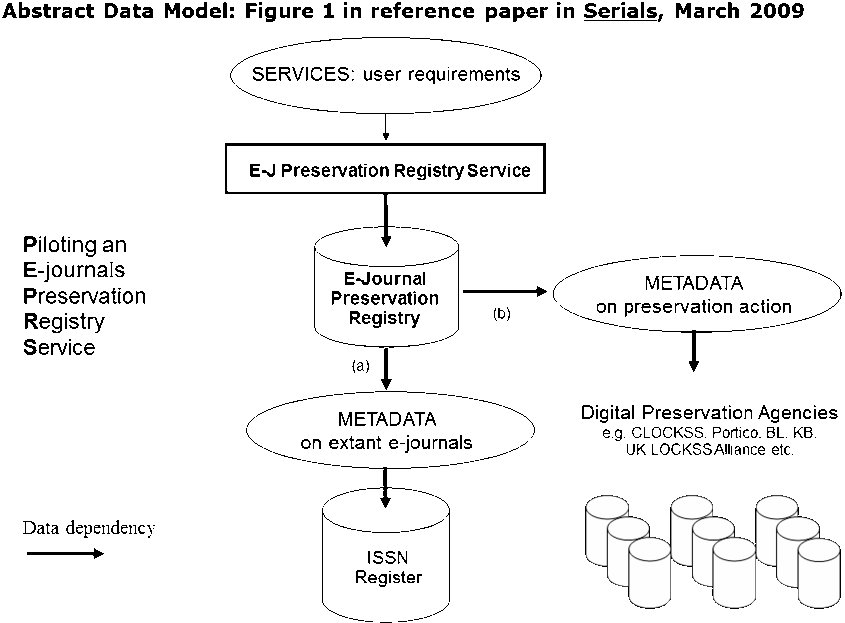
In order to make the project manageable, the scope of electronic serials was limited only to those for which an ISSN had been assigned. Fortunately the ISSN Network had been giving priority to the assignment of ISSN for electronic 'continuing resources', and the number of ISSN assigned rose dramatically during the period that the project began, reaching about 100,000 in 2012, and covering the vast majority of commonly used e-journals.
The prototype for the (PEPRS) e-journal registry was opportunity to use the ISSN-L linking field. [21] The ISSN-L has been devised by the ISSN Network to provide linkage between ISSN records for the same title, recalling that each of the electronic and print versions (manifestations) of the same serial title has separate ISSN and therefore separate ISSN record. One could term this a 'family identifier'.
Use of the ISSN-L has proved valuable at ingest of metadata from the archiving organisations, for those instances when the publisher providing those organisations with an ISSN relating to the printed version as metadata for digital content. The use of the ISSN-L as a kernel within the registry also enables a 'forgiving' and user-friendly response to users who opted to enter the ISSN for a print version into the search box.
Re-named as The Keepers Registry [22] and launched at the annual Meeting of Directors of ISSN Centres held in Sarajevo, Bosnia, and Herzegovina in October 2010, the results of the project are available as an online facility. Perhaps the best way to appreciate what it can do is to try it, at
http://thekeepers.org and then to check the roadmap for forthcoming enhancements, including the upload of a list of ISSN which would assist a library discover whether subscribed online journals were being archived sufficiently.There were initially five archiving organisations in the PEPRS project, providing test data: CLOCKSS [23] & Portico [24]; e-Depot [25] and British Library [26]; the Global LOCKSS Network [27]. During the second phase of the project, two other archiving organizations joined in: the National Library of Science of the Chinese Academy of Sciences [28] and HathiTrust [29].
The inclusion of HathiTrust, which is an archive for content that has been digitised from print sources, has put focus upon the assignment of ISSN for digitised content, typically what was on a library shelf. Aggregating metadata records for the 'buckets' of digitised content from the volumes on shelves, taken from what was written on the spine, and cross-checking against the ISSN Register, it was possible to estimate that as many as 250,000 serial titles (not all journals) were represented, and that very few of the printed serials had had an ISSN assigned. On the one hand the richness within HathiTrust is impressive, including many older titles that were published in Europe, and now are digitised. On the other there is much work ahead to have ISSN assigned, and the Keepers Registry only records archival activity for a small initial subset of 3,820 serials. Knowledge of what was excluded provided a stimulus to consideration that the ISSN Network was already beginning to give to the rules for assigning ISSN to 'digital reproductions'. A debate ensued: was this to be regarded as equivalent to an electronic serial and have the same ISSN, was the ISSN for the printed serial appropriate, or was a separate and new ISSN for the digitized serial required?
The outcome was reported as an update in the ISSN Manual, as announced in the June edition of the ISSN Newsletter. [1] That states the rule that "A single ISSN is assigned to identify all online versions made available under the same title including: versions digitized from print [and] born digital versions" (section 2.2.3). This means that the same ISSN applies to all digital versions of an online resource: one opinion is that this is implicit recognition that the digital format is becoming the mainstream, and that print format requires special assignment of a separate ISSN, in view of its fixity in contrast to the malleability of digital. The update to the ISSN Manual also includes the rules on the assignment of ISSN to digital reproductions of ceased print serials (section 0.6.4) including circumstances when a digitized version is provided by an institution such as a library or an archives provider.
This is only one of the 'serial issues' that were raised during the project in a practical way; a fairly full account is given in Burnhill (forthcoming). [30]
In February 2011, the Society of College, National and University Libraries (SCONUL) in the UK welcomed the news that the development of a shared service for electronic resource management (ERM), including support for the management of licensing information, was to be funded by HEFCE via JISC. That has led to what is known as KnowledgeBasePlus (KB+). Phase I of the project aimed to develop a centralised, shared, above-campus knowledge base of data useful to electronic resources management: to provide institutions, and the services they use, with timely, accurate, verified and structured ERM information, including e-resources publication, licensing, subscription and entitlements data. [31] [32] [33]
Rather than attempt to describe a moving target as KB+ is still in project mode, what follows is a summary of the problem space and associated projects.
As remarked when discussing Figure 3, the assurance of continuity of access to scholarly material in the form of e-journals is an important matter for all academic and research libraries: back content is important. What was once to hand as printed volumes on the shelf is now digital: seemingly more convenient but is held remotely by a publisher or a third party. The concern is not only for long-term preservation but also the ease and assurance of access to back content in the event of cancellation of current subscription, a prospect now pressing because of cuts to library budgets.
In 2009, EDINA and JISC Collections agreed to work together on a scoping study for an 'entitlement registry', comparable to the 'e-journal preservation registry' in a project called PECAN. The focus was on the NESLi, the national consortium licensing initiative for the UK run by JISC Collections. Clause 8.4 of the NESLi2 model licence specifies the context in which continuity of access is permitted:
8.4 After termination of this Agreement (save for a material breach by the Licensee of its obligations under this Agreement) the Publisher will provide (at the option of the Licensee) the Licensee and its Authorised and Walk-in Users with access to and use of the full text of the Licensed Material which was published and paid for within the Subscription Period, either by i) continuing online access to archival copies of the same Licensed Material on the Publisher's server which shall be without charge; or ii) by supplying archival copies of the same Licensed Material in an electronic medium mutually agreed between the parties which will be delivered to the Licensee or to a central archiving facility operated on behalf of the UK HE/FE community or other archival facility (excluding an archival facility of a STM publisher) without charge; or iii) supplying without charge archival copies via ftp protocol of the same Licensed Material.
With focus on the titles included in NESLi2 agreements, a small number of librarians and publishers were each asked what they thought would be the entitlements and access arrangements for back copy in the event of cancelation of a subscription. On the whole, the librarians were pessimistic and the publishers flexible, but at the heart of this was a lack of agreement on what titles a given institution/library was subscribing to, with at least 3 different sources of 'authority': the institution, the publisher and the subscription agent. The work that would be involved in resolving such differences was envisaged as enormously time consuming, and with changes in title ownership the prospect was of enormous cost and effort on all sides. There was call for a subscriptions database with history, recognising that not only were the knowledgebase used for OpenURL link resolvers expensive in time and effort to populate, they overwrote subscription history. The report from that project is available. [34]
There is not scope here to list all current initiatives that use the ISSN as a key identifier, directly or in some embedded form, but here are two. The first is
the Journal Usage Statistics Portal (JUSP) [35] which was developed and is hosted by Mimas, EDINA's sister organisation. This portal provides a "one-stop shop" where libraries can view and download their own usage reports from publishers participating in NESLi2. The other is the KBART format. [36]
The spotlight has been upon the essential role of the ISSN. Important actions taken by the ISSN Network in recent years include the priority given to assignment of ISSN to e-serials (e-journals), tackling the backlog with several large publishers who were slow in adopting separate ISSN for e-content.
The principal advantages of the ISSN as a dumb number are the ease of verification in all sorts of transactions about serials and articles. In particular use of the ISSN avoids the tedium and error associated with matching and disambiguating the text in a variety of fields that describe a serial title, thereby providing ease and accuracy of matching across different automated systems.
There are many examples that could be described. Three or four examples stand out from the point of view of a research or university library. The first is when researchers and students, having discovered the reference or citation to an article within journal, then want to request and access a service on that reference. The use is said to be implicit because, if the different automated systems are 'well-seamed' by interoperability that makes use of the ISSN, the end user need not know about the ISSN except that it should form part of the bibliographic reference (citation).
There are others uses when a library is making decisions about taking out or renewing subscriptions for particular journals or bundles of journals. The second is when providing knowledge to a subscription database that provides authorisation for online access by patrons (researchers and students, say) of a particular library. A third is the basis of computation to provide usage statistics of a given journal (or bundle of journals). The following graphic, as Figure 5, brings this all together, noting the significance of other dumb numbers.
Figure 5: Abstract Data Model for Serial Content
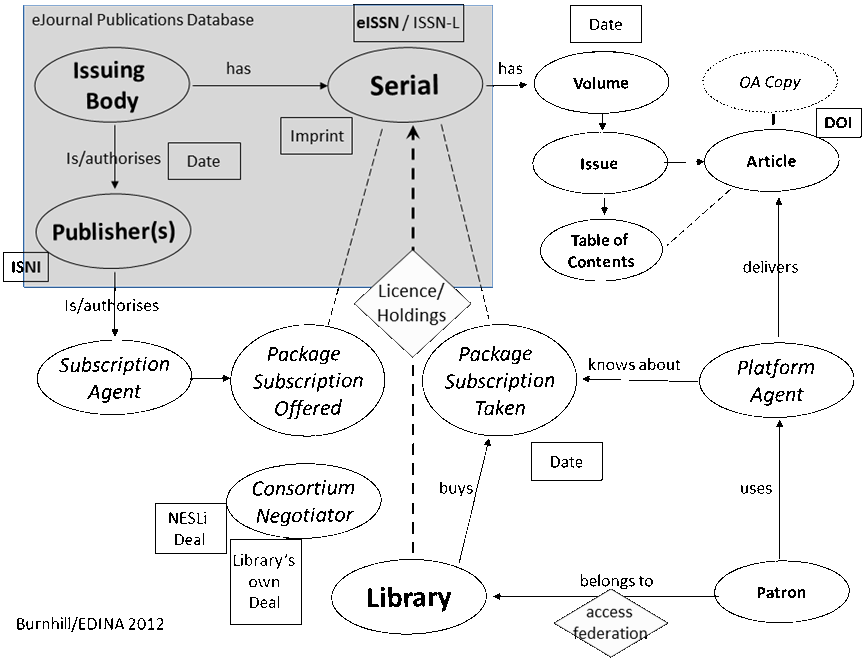
No identification scheme can operate in isolation. Interoperation with two other schemes have been noted and require attention in the near future. One is the URI, an identifier that is central to the operation of the Web, with need for the logical structure of the ISSN Register to be represented within the Semantic Web. The other is the DOI, an identifier that is central to the operation of publishers.
The invention, implementation and availability of the ISSN-L linking field within each ISSN record are also of major significance. This may side step some important questions about the mainstream position occupied by 'the digital' but it is a pragmatic approach that has the effect of bridging the two principal manifestations: the digital and the print. The ISSN-L has utility as the key field within systems, such as The Keepers Registry but potentially also union catalogues. It directly addresses many problems that could arise given the occurrence in different metadata of two different ISSN for the same serial (title).
At present the ISSN-L is a field in an ISSN record, not an identifier within the ISSN Register for an entity representing 'the title'. ISSN-L might yet come to be an identifier that has currency as a 'record' in a variety of systems. We should look to the role for the ISSN-L as the URI for the relationship (predicate) between the separate ISSN of different manifestations in RDF triples of the Semantic Web.
Clearly, there is huge value in having online access to the vast back runs of serials, and for that an identifier is needed. The adoption of rules for the assignment of ISSN for digitised journal content (d-journals) is a bold step forward, with full consequence yet to be realised.
Peter Burnhill, EDINA - University of Edinburgh, e-mail: p.burnhill@ed.ac.uk
[1] <http://bari2012.cimedoc.uniba.it/slide_pres/Burnhill_ult.pdf> <http://www.slideshare.net/edinadocumentationofficer/using-a-dumb-identifier-to-do-smart-things>.
[2] "ISSN Newsletter" 5, June 11 (2012), ISSN 2221-8009, <http://www.issn.org/2-24139-The-newsletter.php?id=40>.
[3] S. A. Dodd, Cataloging machine-readable data files: an interpretive manual, Chicago, American Library Association, 1982.
[4] Ironically, product of that effort is not (yet) online but may be found at the National Library of Scotland and the Library of the University of Sheffield in
P. M. Burnhill - A. Carruthers - A. Messer, Bibliographic control of research data, [Edinburgh], Regional Research Laboratory for Scotland, 1988, Working paper (Regional Research Laboratory for Scotland), n. 6, held by National Library of Scotland, Sheffield.
[5] <http://www.ukoln.ac.uk/dlis/models/>.
[6] Andy Powell, Unique Identifiers in a Digital World, "Ariadne" 8 (1997), <http://www.ariadne.ac.uk/issue8/unique-identifiers/>.
[7] Lorcan Dempsey - Rosemary Russell - Robin Murray, A Utopian place of criticism: brokering access to network information, "Journal of Documentation", 55 (1999), 1, p. 33-70, <http://www.ukoln.ac.uk/dlis/models/publications/utopia/>; <http://www.ukoln.ac.uk/metadata/publications/dlis/utopian-place-of-criticism.pdf>.
[8] <http://edina.ac.uk>.
[9] JISC is in the process of changing its status in order to be more effective and accountable in its role as the innovation and service organization for higher and further education in the UK, <http://www.jisc.ac.uk>.
[10] <http://www.issn.org>.
[11] <http://casa.unibo.it/meetings/bull1eng.html>.
[12] It was very pleasing to meet again with Professor Jacopo Di Cocco who had provided vision and leadership, together with Alexandra Citti and Vincenzo Verniti who lent coherence to the project.
[13] A. Bollini - J. Di Cocco - P. Burnhill, Telematics for Libraries CASA Project, (1998), <http://www.exploit-lib.org/issue2/casa/index.html>.
[14] A. Bollini- P. Burnhill, Distributed SSD Prototype Feasibility Study. CASA Public Technical Deliverable TD18.0/0038, 1999.01.19, <http://www.casa.issn.org:1999/doc/Public_TD/TD18-0038.doc> [Broken].
[15] Sandy Shaw, The JOIN-UP Programme: Seminar on Linking Technologies, "Ariadne", 28 (2001), <http://www.ariadne.ac.uk/issue28/join-up/>.
[16] <http://en.wikipedia.org/wiki/OpenURL>.
[17] <http://openurl.ac.uk/doc/>.
[18] P. Burnhill - L. Halliday - S. Rozenfeld - T. Kidd, SUNCAT: a modern serials union catalogue for the UK, "Serials", 17 (2009), 1, p. 61-67, <http://uksg.metapress.com/content/c6y0ltjtxlhrgfr9/>.
[19] <www.suncat.ac.uk>.
[20] P. Burnhill - F. Pelle - P. Godefroy - F. Guy - M. Macgregor - A. Rusbridge - C. Rees, Piloting an e-journals preservation registry service, "Serials", 22 (2009) 1, [UK Serials Group], <http://uksg.metapress.com/link.asp?id=350487p5670h0v61>.
[21] <http://www.issn.org/2-22637-What-is-an-ISSN-L.php>.
[22] <http://thekeepers.org>.
[23] <http://www.clockss.org/clockss/Home>.
[24] <http://www.portico.org/> .
[25] <http://www.kb.nl/hrd/dd/index-en.html>.
[26] <http://www.bl.uk/aboutus/stratpolprog/legaldep/#elec>.
[27] <http://www.lockss.org/>.
[28] <http://english.las.cas.cn/>.
[29] <http://www.hathitrust.org/about>.
[30] P. Burnhill, Monitoring Archiving with Issues about Serials on the Web: The Keepers Registry, "Serials Review" (accepted; under revision).
[31] <http://www.jisc-collections.ac.uk/KnowledgeBasePlus/>.
[32] <http://sconulerm.jiscinvolve.org/wp/>.
[33] <http://helibtech.com/SCONUL_Shared_Services>.
[34] <http://www.jisc-collections.ac.uk/Reports/Pecan-Report/>.
![]()
![]()
![]()