![]()
![]()
![]()
![]()
![]()
![]()
Questa sera si cataloga a soggetto. Breve analisi delle folksonomies in prospettiva bibliotecaria
![]()
La capacità di riconoscere e definire il significato di oggetti, concetti e fenomeni del reale è qualcosa di profondamente connaturato al nostro essere: come infatti hanno dimostrato numerosi studi, l'espressione dei contenuti ed il loro inserimento in categorie più o meno omogenee, si caratterizza come una precisa attività cognitiva, una funzione della mente. [1] Ed è interessante che tale funzione abbia trovato una sua peculiare applicazione alle biblioteche, dove sono stati messi in atto una serie di meccanismi volti a individuare e descrivere il contenuto concettuale dei documenti: [2] difatti non è un caso se, fin dai tempi più remoti, le strutture bibliotecarie hanno dato vita a tecniche di classificazione o a modalità (chiamiamole così) di indicizzazione per soggetto, che si sono gradualmente consolidate fino a diventare uno dei cardini dell'attività professionale, oltre che uno degli aspetti più rilevanti della riflessione biblioteconomica. [3]
Quello semantico è dunque un versante a cui il mondo bibliotecario è molto sensibile, in particolare nell'epoca odierna, nella quale le procedure automatizzate e le potenzialità della rete hanno apportato una quantità di vantaggi legati non solo all'efficacia e alla celerità nelle ricerche, ma all'ampliamento su scala globale delle possibilità di esplorazione e recupero delle informazioni.
D'altra parte la presenza di sistemi di ricerca sempre più sofisticati ha notevolmente accresciuto le capacità degli individui, che si trovano a proprio agio tanto nello sfruttamento di sofisticati strumenti quali banche dati, archivi informatici, datawarehouse etc., quanto nell'utilizzo di sistemi un tempo ritenuti esoterici come gli operatori booleani e di prossimità, o i meccanismi di filtro, di troncamento, di mascheramento e così via. [4]
È dunque singolare che un popolo di ricercatori qual è stato finora quello del web possa trasformarsi repentinamente in un popolo di indicizzatori, capaci di riconoscere e descrivere il contenuto di una quantità di oggetti presenti in rete: eppure è ciò che sembra accadere se è vero che, tra le nuove opportunità offerte da Internet, quella volta ad assegnare parole chiave a concetti e oggetti si sta imponendo con particolare vigore. Il fenomeno a cui facciamo riferimento è ovviamente quello delle folksonomies, e cioè la possibilità, concessa agli utenti della rete, di attribuire una serie di termini (o "tags", come vengono per lo più definiti) a un gran numero di risorse e pagine web.
Siamo di fronte a una sollecitazione assai potente e suggestiva, dal momento che i frequentatori del web possono non solo scambiarsi file nei formati più diversi, "postare" le proprie opinioni sui blog o "duplicare" se stessi e le proprie attività su Second Life, [5] ma anche - alla lettera - catalogare a soggetto, assegnando parole chiave a una varietà di oggetti, libri inclusi.
Non è un caso dunque se per molti analisti le folksonomies, insieme ai blog, ai wikis e ai feeds RSS, rappresentano la nuova frontiera della rete, venendo a costituire ciò che è stato definito il "Web 2.0", [6] ossia una dimensione in cui ogni utente può trasformarsi "da consumatore a partecipante, da utilizzatore passivo ad autore attivo di contenuti, messi a disposizione di chiunque si affacci su Internet". [7]
E tuttavia si discute molto se tali strumenti siano davvero in grado di dar vita a una prospettiva totalmente inedita, e dunque a una svolta radicale nella vicenda stessa di Internet. In realtà numerosi osservatori sono convinti che i nuovi applicativi possano senz'altro accrescere i livelli di condivisione e di partecipazione realizzati dagli utenti, ma che questo non basti per parlare di cambiamento epocale: difatti, ciò a cui assistiamo sembra più che altro un'evoluzione, uno sviluppo di potenzialità già esistenti, [8] innescate dagli strumenti "classici" della rete quali la posta elettronica, le chat lines e le liste di discussione; favorite dalla proliferazione di forum, gruppi d'interesse e comunità virtuali; e infine consolidate (e, vorremmo dire, messe in grado di operare) dalla quantità di informazioni utilizzabili in modo assai efficace grazie ai linguaggi di marcatura e alle modalità ipertestuali.
Se dunque il Web 2.0 si può considerare un ampliamento di una tendenza (o, se si vuole, di una tensione) alla partecipazione e alla condivisione in Internet, [9] ciò è dovuto senz'altro alle capacità delle tecnologie che ne stanno alla base. E come spesso accade di fronte a innovazioni di particolare successo, a queste tecnologie si assegna oggi un'enfasi straordinaria, esaltandone la superiorità rispetto ad ogni altra componente, e affermando che grazie ad esse si può realizzare un progressivo e indefinito miglioramento. [10]
Ovviamente un rischio del genere coinvolge anche le folksonomies: porre tutta l'attenzione sugli aspetti tecnologici infatti può portare a una riduzione della forte carica cognitiva legata all'individuazione e all'attribuzione dei contenuti, e ciò può indurre gli utenti a esercitare questa attività in modo neutro e quasi inconsapevole, appiattendo - per dir così - una serie di scelte che avrebbero potuto avrere ben altri risultati.
Per contro, osserva Olivier Le Deuff, "l'impiego di parole chiave non è mai neutro": [11] proprio perché ha a che fare con l'espressione dei contenuti, questa pratica comporta infatti una serie di conseguenze di natura epistemologica (ossia relativa ai livelli di conoscenza che vengono attiviati), ermeneutica (cioè connessa a interpretazioni più o meno corrette del concetto preso in esame) ed infine etica (legata alla possibilità di condizionare in un senso piuttosto che in un altro tale concetto). [12]
E se è vero che si insiste molto sulle caratteristiche partecipative e di condivisione che informano il fenomeno (il termine più impiegato per esprimerlo, non a caso, è quello di social tagging), è altresì vero che i complessi problemi a cui si è fatto cenno non risultano finora sufficientemente esplorati, e ciò può lasciare ampie zone d'ombra nell'impiego odierno e negli sviluppi futuri di questa modalità di attribuzione dei contenuti.
Nelle note che seguono non proseguiremo in tale analisi, cosa per cui occorrono ben altri strumenti; per contro, guarderemo alle folksonomies da un punto di vista squisitamente bibliotecario, provando a esaminarle alla luce della "dimensione semantica" propria delle biblioteche, e quindi con i criteri e i metodi che ci sono stati consegnati da una lunga tradizione pratica e concettuale.
Un'operazione di retroguardia, dunque? probabilmente sì, dal momento che da più parti viene riconosciuta la radicale diversità dell'approccio "folksonomico" rispetto quello bibliotecario. [13] E tuttavia ci sembra che una puntualizzazione di alcuni elementi del discorso, e una sua comparazione con gli orientamenti semantici propri delle biblioteche, possa aiutarci a comprendere meglio un argomento che è di grande interesse per la nostra realtà professionale.
L'idea che le folksonomies siano la nuova frontiera nel campo dell'assegnazione dei contenuti appare quindi assai diffusa fra osservatori e studiosi; ed è un'idea che si propone con forza a partire dal suo stesso nome, se è vero che
la parola folksonomy è un neologismo composto da "folks" (gente) e "taxonomy" (tassonomia). Il termine è stato ideato da Thomas Vander Wal, architetto dell'informazione, che lo ha coniato durante una discussione online. Si tratta quindi di una classificazione "dal basso", creata dagli utilizzatori che attribuiscono una parola chiave, cioè il tag, ad una risorsa messa sul web al fine di condividerla. Le risorse non vengono quindi classificate a priori, ma aggregate dai navigatori/utenti. [14]
Una volta chiarita la natura partecipativa e squisitamente bottom-up del fenomeno, occorre però rilevare che il termine che lo designa è viziato da un'ambiguità di fondo: difatti il significato di tassonomia (e di conseguenza quello di classificazione) è legato non già alla presenza di descrittori in grado di esprimere un determinato contenuto, ma alla capacità di dar vita a distribuzioni categoriali di concetti. Come infatti si legge nell'omonima voce della Wikipedia,
con il termine tassonomia (dal greco "taxinomia", dalle parole taxis = ordine e nomos = regole) ci si può riferire sia alla classificazione gerarchica di concetti, sia al principio stesso della classificazione. Praticamente tutti i concetti, gli oggetti animati e non, i luoghi e gli eventi possono essere classificati seguendo uno schema tassonomico. [15]
Si può dunque ritenere che l'espressione "folksonomy" sia stata coniata in modo quanto meno affrettato, dal momento che gli utenti della rete non sono chiamati a dar vita a classi di concetti, ma a individuare una serie di contenuti e offrirne una propria definizione. [16] Difatti il concetto di tassonomia (o, se si preferisce, di classificazione) implica sempre un'idea di distinzione, di ripartizione categoriale: dunque non una mera enumerazione di oggetti e fenomeni, ma un loro ordinamento in categorie più o meno omogenee.
In altre parole, il processo della classificazione dà vita a insiemi di concetti che vanno a raccogliersi in gruppi (le classi) a seconda del loro grado di somiglianza o di affinità, mentre separa quelli aventi caratteristiche diverse: tutti i membri di una classe devono infatti condividere almeno una caratteristica che i membri di altre classi non posseggono, e ciò permette di raggruppare oggetti o concetti fra loro simili distinguendoli da quelli diversi. È per questo, scrive Eric Hunter, che la classificazione sconfigge il caos, [17] e gli esempi che seguono lo mostrano con chiarezza:

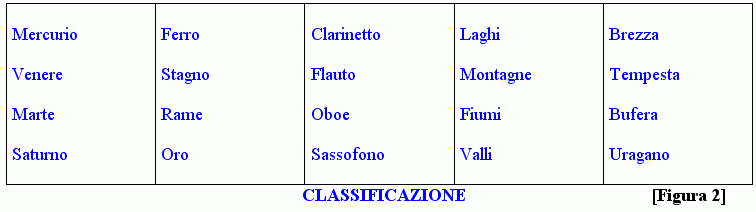
Tuttavia il processo di classificazione non si limita a raggruppare gli elementi simili e a separarli da quelli dissimili ma, all'interno dei singoli gruppi, permette di effettuare ulteriori ripartizioni, fino ad arrivare a elementi non più divisibili; si creano in tal modo delle "sotto-classi", all'interno delle quali si ritrovano caratteristiche che identificano in maniera via via più precisa i propri membri. L'atto del classificare allora non produce solo raggruppamenti più o meno omogenei di oggetti o di idee, ma una serie di suddivisioni (solitamente di tipo gerarchico) in base al grado di somiglianza o di affinità dei suoi componenti.
Nulla di tutto questo avviene nel mondo delle folksonomies, dal momento che i tags vengono assegnati in maniera piatta e orizzontale, senza tener conto delle relazioni - gerarchiche o di altra natura - che intercorrono fra i concetti; ciò non consente di far emergere delle classi, e quindi non giustifica l'idea che, per quanto fatte dalla gente, si tratta comunque di tassonomie.
L'immagine che segue - desunta da un sito che per noi è di grande importanza perché finalizzato ad assegnare parole chiave non a blog o a pagine web ma a oggetti bibliografici fondamentali quali i libri [18] - rende esplicito l'intero discorso. Essa infatti visualizza i tags correlati al concetto di "information tecnology", [19] i quali appaiono tutti sullo stesso piano, [20] non venendo individuati né i possibili i rapporti fra i termini né le loro eventuali ripartizioni gerarchiche, con conseguenze che è facile immaginare, specie nella ricerca di informazioni connesse a concetti semanticamente più ampi o più ristretti di quello preso in esame, o a questo in qualsiasi modo collegate.

Non è un caso dunque se un criterio così piatto ed egualitario di espressione dei contenuti sia stato messo in discussione da numerosi osservatori: Elaine Peterson, ad esempio, rileva come questa modalità si scontri con il principio cardine di ogni organizzazione categoriale, ossia quello basato sulla reciproca opposizione fra concetti diversi. [21]
Difatti i principi della classificazione elaborati dalla logica formale prevedono la divisione della totalità del sapere in classi via via meno ampie, fino ad arrivare a concetti individuali, cioè non più divisibili; il processo logico della classificazione quindi si sviluppa attraverso singoli passi di divisione, che di volta in volta danno vita a due concetti opposti, A e Non-A, producendo classi mutuamente esclusive perché fondate sul possesso o sul non possesso di una determinata qualità. [22]
E tuttavia è evidente che questo modello di divisione per coppie dicotomiche è applicabile solo teoricamente alle classificazioni: l'universo del sapere infatti è in continuo mutamento, e ciò dà vita a una quantità di interazioni sia all'interno delle discipline che fra discipline, rendendo praticamente impossibile un inquadramento di tale sapere in un ordine lineare. Non è quindi un caso se le classificazioni documentarie abbiano spesso ignorato tale modello, spinte dalla necessità di rappresentare un insieme di conoscenze molteplice e complesso, cioè articolato su diversi piani disciplinari e semantici.
Queste considerazioni sono poi alla base della ricca elaborazione concettuale che ha portato all'avvento delle classificazioni analitico-sintetiche e degli altri sistemi basati sulle faccette, [23] nati allo scopo di attenuare - se non di risolvere - i problemi tipici degli schemi tradizionali, derivanti da un'organizzazione strettamente gerarchica, oltre che dall'inclusione di oggetti, concetti e fenomeni del reale in discipline rigidamente definite.
Ed è interessante che tanto le classificazioni gerarchico-enumerative quanto quelle analitico-sintetiche siano diventate oggetto di critica da parte dei sostenitori delle folksonomies, i quali hanno messo in luce non solo le rigidità strutturali e le difficoltà di aggiornamento degli schemi enumerativi, ma anche l'incapacità dei sistemi a faccette di dar conto delle profonde trasformazioni gnoseologiche intervenute in seguito all'avvento delle nuove tecnologie e alla diffusione di Internet.
Clay Shirky ad esempio, in una beffarda analisi sull'arretratezza degli strumenti semantici adottati dalle biblioteche, sottolinea l'incapacità di tali strumenti a rappresentare la complessità del sapere propria dell'epoca odierna: [24] a suo parere infatti le biblioteche sono pervicacemente legate al mondo analogico, le cui conoscenze vengono incapsulate una volta per tutte in oggetti ben definiti quali sono i libri, per poi essere inquadrate nelle rigide maglie di classificazioni obsolete come la Dewey, il cui unico scopo è peraltro quello di collocare gli stessi libri sugli scaffali. Difatti, continua Shirky, per le biblioteche e i bibliotecari
l'essenza di un libro non consiste nelle idee che vi sono contenute; l'essenza di un libro è "libro". Pensare che i cataloghi delle biblioteche esistano per organizzare i concetti significa confondere il contenitore con la cosa contenuta. [25]
In maniera assai più meditata, Emanuele Quintarelli riconosce vantaggi e limiti delle classificazioni documentarie, [26] osservando che sia gli schemi gerarchici sia quelli a faccette danno i risultati migliori quando sono applicati ad ambiti disciplinari relativamente ristretti, non sottoposti a rapidi cambiamenti e non condizionati da caratteristiche di intra- o inter-disciplinarità. E tuttavia, prosegue l'autore, è indubbio che tali condizioni siano ormai inestenti, dal momento che le nuove tecnologie e la diffusione planetaria di Internet hanno radicalmente modificato i presupposti su cui si reggeva il preesistente ordine del sapere, stravolgendo i tradizionali criteri di organizzazione e di utilizzo delle conoscenze. Oggi invece è il web che
si colloca nettamente in questa prospettiva. Sul web la direzione è la scalabilità, la flessibilità, la fluidità e la semplicità, allo scopo di soddisfare il bisogno crescente di milioni di persone con diversi background culturali e sociali in tutto il mondo. In queste circostanze, i convenzionali schemi di classificazione diventano costosi da creare e da mantenere, e probabilmente perdono la capacità di unificare il modo di pensare e di organizzare il mondo che è proprio degli utenti. [27]
Per entrambi gli autori quindi la risposta all'inadeguatezza degli approcci tradizionali non può venire che dalle folksonomies: queste ultime infatti sono prive di condizionamenti culturali o ideologici; non devono fare i conti con pesanti sovrastrutture enumerative o gerarchiche; possono essere utilizzate (ma soprattutto create) da tutti e non solo da una ristretta casta di professionisti; e infine sono in grado di intercettare gli umori semantici, per dir così, di una vasta platea di individui, e dar vita di conseguenza a un efficace recupero delle informazioni ad esse correlate. [28]
Ma se è evidente che i tradizionali sistemi di classificazione non riescono a rappresentare la crescente complessità del sapere, [29] è altresì evidente che la soluzione offerta dalle folksonomies appaia quanto mai insoddisfacente, in quanto prevede l'abbandono (per non dire la demolizione) di qualsiasi struttura semantica predefinita, mentre sarebbe lecito attendersi la creazione di nuovi criteri di organizzazione delle conoscenze, in grado di mettere in sintonia la tendenza all'attribuzione dei contenuti in rete con l'inedita dimensione epistemologica odierna. [30]
Per contro, la prospettiva che emerge dalle folksonomies è quella di una oversimplification in cui, per parafrasare Clay Shirky, viene spazzato via tanto il contenitore quanto la cosa contenuta. Per i sostenitori di questa pratica infatti ciò che conta è da un lato la partecipazione di un numero vasto di persone all'attività di tagging, [31] dall'altro l'impiego di termini che, come dice Thomas Vander Wal, siano il più possibile "parlanti", cioè in grado di essere condivisi da una comunità assai ampia di utenti; di conseguenza non è importante (o meglio, non è opportuno) che questi termini facciano riferimento a strutture semantiche predefinite, né che siano collegati a nuove forme di definizione dei contenuti, in grado di esprimere a pieno una realtà articolata e dinamica com'è l'attuale.
Le folksonomies dunque non sembrano rispondere a uno dei principali requisiti per cui sono nate, ossia quello di rispecchiare le nuove e più elaborate forme di sapere proprie dell'epoca odierna; di seguito proveremo a verificare il secondo, importante postulato che le caratterizza, e che attribuisce loro la capacità di reperire una rilevante quantità di informazioni presenti in rete.
A questo scopo effettueremo un'indagine parallela tra i meccanismi di ricerca tipici di questa modalità e quelli tradizionalmente messi in atto dalle biblioteche. Ma per far ciò, è opportuno ricordare che le capacità di recupero di un sistema documentario vengono accresciute dall'impiego di strumenti che siano "controllati" non solo da un punto di vista epistemologico (cioè per rappresentare in modo scientificamente corretto l'universo delle conoscenze), ma anche sotto un profilo semantico, allo scopo di ridurre la complessità e la variabilità dei linguaggi naturali, oltre che mettere in luce la rete di relazioni esistenti fra i termini.
Ed è proprio quest'ultimo aspetto che assume un'importanza particolare, venendo a costituire l'essenza stessa delle classificazioni, ed essendo presente tanto nei sistemi di indicizzazione basati sui soggettari (in cui dà vita al cosiddetto apparato sindetico), quanto in quelli che impiegano i thesauri, nei quali le relazioni fra i termini sono rappresentate in modo decisamente esplicito. Le immagini che seguono lo dimostrano con chiarezza; la prima, proveniente dal Thesaurus Inis di scienze nucleari, identifica le connessioni fra i termini attraverso le sigle che esprimono le relazioni gerarchiche (BT, NT), di affinità (RT) e di equivalenza (USE, UF), oltre che sulla base di evidenti meccanismi di indentazione.
|
|
[Figura 4]
La seconda immagine, scaturita da una ricerca via web effettuata sull'Art and Architecture Thesaurus, dimostra come sia possibile sfruttare a pieno le potenzialità della rete per rendere evidenti non solo i rapporti fra i termini, ma le connessioni fra questi e le categorie di riferimento, in coerenza con la natura a faccette del thesaurus medesimo.
|
|
[Figura 5]
Un'indicizzazione basata su questi strumenti dunque consente di riconoscere i collegamenti fra i termini; di "disambiguare" i concetti a seconda del contesto tematico di riferimento; e infine di eliminare i problemi di sinonimia, omofonia, omografia e omonimia che sono assai frequenti nel linguaggio naturale. In tal modo si possono individuare le voci più idonee per descrivere un determinato concetto; ciò accresce l'efficacia della ricerca, e quindi la soddisfazione dell'utente, il quale ottiene risposte più aderenti alle sue richieste informative.
Ma si è visto che i fautori delle folksonomies, in nome di un'assoluta libertà d'uso da parte degli utenti, sono decisamente contrari all'impiego di strumenti di controllo terminologico, privandosi in tal modo dei vantaggi che derivano da queste forme di indicizzazione. Al giorno d'oggi però possiamo notare che i problemi relativi al recupero delle informazioni ad esse correlate cominciano a essere presi in considerazione anche da osservatori non legati ai tradizionali sistemi documentari; Isabel de Maurissens, ad esempio, rileva che il limite maggiore delle folksonomies consiste proprio "nell'information retrieval":
trovare una risorsa, sì, ma con quali parametri? Non abbiamo nessuno strumento tradizionale a disposizione. Bisogna affidarsi al senso comune che viene dato ad una parola. Infatti la stessa risorsa può essere descritta in diversi modi e questo crea confusione. Ad esempio, per descrivere la "comunità di pratica" potranno essere usati i seguenti tags: community of pratice, educazione non formale, conoscenza, diffusione dell'informazione, processo di apprendimento, apprendimento collaborativo, apprendimento di gruppo. [32]
Per parte sua Nicola Benvenuti riconosce che la ricerca tramite folksonomies è priva di efficacia tanto nel grado di richiamo (ossia il numero di documenti pertinenti recuperati rispetto al totale dei documenti pertinenti), quanto in quello di precisione, cioè il numero di documenti pertinenti rispetto al numero di documenti recuperati. [33]
Ora, sappiamo che l'obiettivo dei tradizionali linguaggi d'indicizzazione è quello di massimizzare congiuntamente le capacità di richiamo e di precisione, che invece tendono ad essere inversamente proporzionali: in seguito a una ricerca con un determinato descrittore infatti si può ottenere o un numero elevato di risposte che includono solo marginalmente l'argomento desiderato (dando vita così a un alto grado di richiamo), o un numero ristretto ma piuttosto pertinente di risposte (producendo cioè un alto grado di precisione). Il fatto che le folksonomies non consentano di realizzare efficacemente né l'una né l'altra possibilità è un indice della loro estrema debolezza semantica, al punto che cominciano a delinearsi una serie di proposte volte a "sopperire a queste carenze". [34]
Tali proposte sono tanto di tipo tecnico - legate cioè a particolari modalità di elaborazione informatica [35] - quanto di tipo "umano", ossia tese a elaborare una serie di linee guida allo scopo di migliorare la qualità del tagging; quest'ultimo percorso è stato intrapreso in particolare da Ulises Ali Mejias il quale, pur ribadendo la fiducia nelle capacità "indicizzatorie" proprie delle folksonomies, ha fornito alcune indicazioni finalizzate a rendere il loro utilizzo meno disorganico e superficiale.
E se in alcuni casi le proposte dell'autore appaiono piuttosto generiche (come quando invita a privilegiare termini che, oltre a esprimere il punto di vista dell'utente, siano anche socialmente condivisi; o quando chiede di limitare l'uso di vocaboli tecnici o idiosincratici), gli esiti a cui giunge appaiono come un primo tentativo di "normalizzazione" delle folksonomies, centrato sul corretto uso del singolare e del plurale, oltre che sulla possibilità di definire in modo più esplicito le sinonimie, e sull'opportunità di collegare tramite underscore i termini composti (come nel caso di "open_source"), al fine di ridurre la dispersione e ottenere risposte più soddisfacenti e mirate. [36]
Prendendo spunto da queste osservazioni, Marieke Guy ed Emma Tonkin ritengono che sia possibile migliorare ulteriormente la qualità del tagging attraverso una serie di "norme" volte a definire in modo più adeguato le parole chiave. Le autrici infatti non solo ribadiscono l'importanza di un uso oculato del singolare e del plurale, ma si soffermano su un aspetto che nei linguaggi di indicizzazione ha un ruolo cruciale, e che invece è del tutto assente nel mondo delle folksonomies, vale a dire l'ordine di citazione; nelle parole di Guy e Tonkin,
quando etichetto una foto, posso usare dei tags per descrivere un gatto nero e un cane bianco. Ma una volta che i diversi tags ("nero", "gatto", "bianco", "cane") sono inclusi nella base di dati, il loro significato si perde; gli utenti che fanno una ricerca non sanno più quale animale è bianco e quale è nero. [37]
Ma oltre alla necessità di individuare un criterio univoco di rappresentazione dei concetti, nell'analisi delle autrici comincia anche a vacillare uno dei principi fondativi delle folksonomies, ossia quello che le vuole diverse e distanti da qualsiasi forma di ripartizione gerarchica: Guy e Tonkin infatti rilevano come sempre più spesso gli utenti diano vita a "pseudo-gerarchie private di termini, nel momento in cui stabiliscono convenzioni che ricordano le strutture delle directory, quali ad esempio 'Programming/C++', o 'Programming/Java', o 'Programming/HTML'". [38]
Sembra inevitabile, viene da commentare, che per ovviare alle loro intrinseche debolezze le folksonomies debbano spostarsi verso i criteri propri dei linguaggi documentari, che prevedono non solo un idoneo controllo del vocabolario, [39] ma anche l'individuazione delle relazioni fra i termini, e dunque il riconoscimento di vere e proprie forme di gerarchia; quanto velocemente ciò possa accadere, è cosa che potremo apprendere continuando a osservare il fenomeno.
Una volta definiti i confini entro i quali si muovono le folksonomies, è ora opportuno verificare "sul campo" le modalità attraverso cui esse operano, e gli esiti ai quali danno vita tanto nella fase di definizione dei significati quanto in quella di ricerca. Inizieremo questa analisi da Library Thing, ossia il sito che, come si è visto, permette agli utenti di assegnare tags a libri di saggistica e di narrativa; proveremo quindi a confrontare questi tags con i "prodotti" della Library of Congress, allo scopo di valutare in modo parallelo queste modalità di descrizione dei contenuti.
Ed è senz'altro interessante che, nell'epoca della multimedialità e di Internet, abbia preso vita un'iniziativa che consente non solo di esprimere un commento o di scrivere una recensione, [40] ma di analizzare il contenuto semantico di un intero libro e sintetizzarlo in una serie di parole chiave; [41] ai fini del nostro discorso tuttavia è più importante esaminare i criteri con cui si sviluppa questa forma di indicizzazione, e confrontarne gli esiti con quelli realizzati dalla principale agenzia bibliografica statunitense. Partiamo quindi con una rapida analisi di due opere di saggistica, per poi passare a due testi di narrativa.

Siamo di fronte a un testo che già dal titolo appare sufficientemente espressivo del suo contenuto semantico; ma se guardiamo ai soggetti della Library of Congress, notiamo come essi mettano l'accento sul concetto di "relazioni internazionali", oltre a fornire precise determinazioni temporali e a chiarire il punto di vista con cui si sviluppa il discorso. Comprendiamo di conseguenza che si tratta di un'analisi sulla filosofia delle relazioni internazionali degli Stati Uniti dal ventesimo secolo a oggi, e che essa viene interpretata come una forma di imperialismo.
Ora, è difficile ricostruire quest'insieme di significati sulla base delle folksonomies attribuite al documento, e non solo perché molti tags risultano quanto mai generici, ma perché anche voci più specifiche quali "Imperialism" sono confuse fra una quantità di termini spesso privi di significato ("unread"), o volti a indicare un ambito generale di appartenenza ("non-fiction"). D'altra parte l'assenza del termine-chiave "United States" non solo impedisce di definire con precisione il campo semantico del documento, ma aumenta notevolmente il "rumore" in fase di ricerca, [42] dal momento che descrittori significativi come "Imperalism" possono essere riferiti ad altri paesi o periodi storici. Per contro, abbondano ciò che definiremmo vere e proprie "classi generali" ("world history", "modern history"; "politics"), ed anche alcune voci "ampie" ma che comunque possono essere correlate all'argomento (come ad esempio "political history") risultano prive di efficacia, perché ad esse non sono associati termini in grado di specificare adeguatamente i concetti.

Il secondo esempio ci mostra un'opera dal titolo ugualmente "parlante", per quanto i suoi contenuti vengano ulteriormente chiariti dalla Library of Congress, che fornisce non solo due soggetti piuttosto espliciti, ma anche l'indice della monografia, grazie al quale possiamo avere un'idea non approssimativa degli argomenti e delle modalità con cui sono discussi dall'autore.
Le folksonomies invece ci restituiscono un quadro molto disomogeneo: come nell'esempio precedente, troviamo infatti voci eccessivamente vaste ("World Politics", "american history"); ridondanze e assenza di normalizzazione (ad esempio nei diversi modi con cui è scritto il nome del presidente americano); termini asemantici o fuori contesto ("read in 2006", "journalism"); e infine espressioni generiche e indifferenziate ("army", "current events").
È peraltro interessante verificare i risultati che questi termini producono nel momento in cui sono utilizzati per nuove ricerche. Trascurando le voci troppo ampie o manifestamente prive di significato, e provando a selezionando "iraq war" (ossia il descrittore più indicativo del contenuto del documento), vengono visualizzate 21 monografie, tutte - almeno a giudicare dai titoli - piuttosto pertinenti. Se invece si seleziona il soggetto "Iraq war - 2003" della Library of Congress, il sistema restituisce 573 riferimenti, che non solo risultano decisamente pertinenti, ma anche disponibili in più lingue e in formati diversi (audiovisivi, risorse elettroniche, etc.).
Ora, pur riconoscendo la diversa dimensione quantitativa delle due basi di dati, è evidente che la ricerca condotta sul catalogo della Library of Congress appare vantaggiosa sia dal punto di vista del richiamo che della precisione, oltre a permettere di "raffinare" ulteriormente la ricerca aggiungendovi altri termini significativi, o filtrandola per anno, per lingua, per tipo di documento, e così via. Anche in questo caso dunque non si può che confidare in un'apertura delle folksonomies verso modalità più consolidate dal punto di vista documentario.

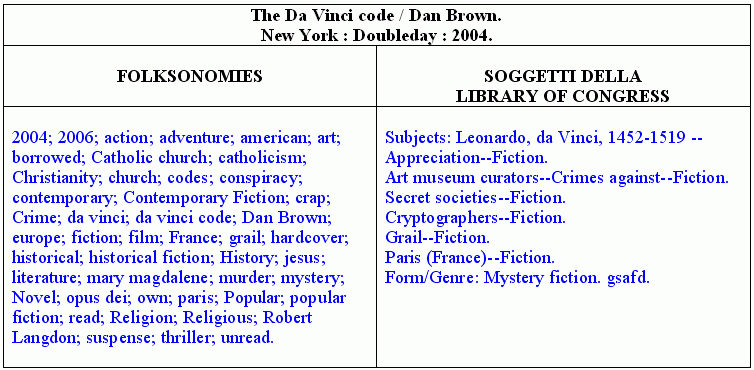
Gli ultimi titoli presi in esame risultano particolarmente interessanti perché, pur essendo testi di narrativa, hanno ricevuto dei veri e propri soggetti dalla Library of Congress; si tratta di una tendenza che comincia ad affermarsi in diversi ambienti bibliotecari, e che ha lo scopo non solo di enucleare gli aspetti più rilevanti di un'opera, ma anche di portare alla luce quelle che F. Wilfrid Lancaster definisce "informazioni sostantive", cioè in grado di fornire al lettore dati e notizie capaci di ampliare in modo significativo le sue conoscenze. [43]
E se confrontiamo questi soggetti con le parole chiave assegnate dagli utenti, notiamo che in essi vi è un tentativo di esprimere sinteticamente i contenuti narrativi di cui non c'è traccia nelle seconde: le folksonomies infatti presentano la consueta abbondanza di voci asemantiche ("hardcover", "Novel"), idiosincratiche ("Great Book", "borrowed", "unread"), o fuori contesto ("translation", "film"), oltre a termini eccessivamente ampi e non adeguatamente correlati ("European literature", "Catholic church").
Appare peraltro evidente la mancanza di un ordine di citazione che consenta di collegare i termini in modo appropriato, e dar vita così a una "stringa coestesa", ossia capace di definire in modo unitario i diversi concetti presenti nel documento: un po' come nel primo caso è riuscita a fare la Library of Congress, nel momento in cui ha creato il soggetto "Napoleonic Wars, 1800-1815 - Campaigns - Russia", cioè l'informazione maggiormente sostantiva che può offrirci il capolavoro di Tolstoj.
I tags presenti nel secondo esempio non si discostano dalla maniera dispersiva e quasi polverizzata di espressione dei contenuti che è propria delle folksonomies: i diversi elementi del romanzo infatti sono rappresentati da una quantità di voci inframezzate da termini semanticamente vuoti, e dunque inutilizzabili - anzi svantaggiosi - ai fini del recupero. Ne consegue non solo l'impossibilità di ricostruire in modo organico il contenuto dell'opera, [44] ma anche la difficoltà di raggiungere altri documenti ad essa collegati.
Ma ovviamente non sono soltanto i libri ad essere presi in considerazione nell'attività di tagging, se è vero che una quantità di risorse di rete (fotografie, blog, pagine web, etc.) ricevono parole chiave con frequenza assai elevata; di seguito quindi esamineremo i principali siti che adottano le folksonomies, provando a cogliere le affinità e le differenze con i sistemi in uso nelle biblioteche.
Partiamo da Flickr, un ricchissimo contenitore di fotografie realizzate dagli utenti, [45] in cui possiamo notare l'adozione di un criterio a suo modo classificato, dal momento che le immagini visualizzate in seguito a una ricerca vengono suddivise in "most relevant", "most recent" o "most interesting". Un'analoga forma di ripartizione si ha nel caso di ricerche basate su termini particolarmente ampi: se ad esempio si inserisce la parola chiave "jazz", si ottengono tre insiemi semantici, che però - come mostra l'immagine seguente - non seguono un andamento gerarchico, ma sono presentati in maniera piuttosto arbitraria.
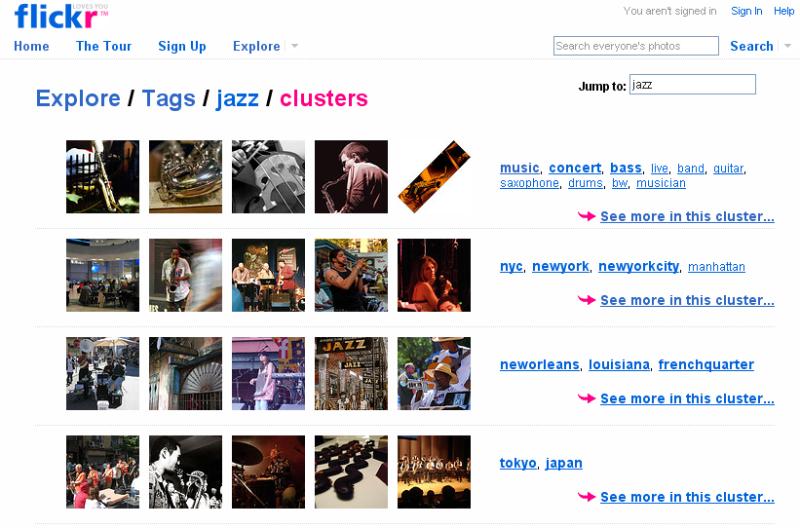
[Figura 6]
E anche se si impiega una voce più specifica, vediamo che i risultati non appaiono molto diversi; per restare all'ambito musicale, proviamo infatti a inserire il termine "post-punk", ed otterremo i seguenti "clusters":

Anche in questo caso insomma ritroviamo la dispersione tipica delle folksonomies, in quanto il termine in questione, che da un punto di vista semantico dovrebbe essere subordinato almeno a "rock music", viene accostato a una quantità di altre voci (fra cui una vera e propria "super-classe" come "music"), producendo notevole rumore nella ricerca di ulteriori items.
Se poi si fa clic sul termine "rock", il risultato è ancora più sorprendente perché, oltre al cluster di ambito musicale, ne vengono visualizzati altri tre appartenenti a categorie del tutto diverse, e ciò la dice lunga sui problemi di sinonimia che affliggono le folksonomies:

Il modello proposto da Flickr dunque riconosce la necessità di forme di ripartizione categoriale, ma non porta fino in fondo questa intuizione attraverso un'idonea suddivisione dei concetti. Analoghe difficoltà, connesse tanto al controllo del vocabolario quanto all'ordine di citazione e alle relazioni fra i termini, sono presenti anche negli altri siti che adottano le folksonomies; per esaminare le modalità da essi impiegate, ci sembra allora utile una breve analisi basata su una unità concettuale che ci è già nota, vale a dire Il codice da Vinci.
Iniziamo da del.icio.us, [46] un sito di social bookmarking che consente agli utenti di condividere una quantità di risorse disponibili in rete. Sono quindi le pagine web a diventare oggetto di tagging, per cui una ricerca con "Da Vinci Code" restituisce una serie di risorse relative al romanzo tra cui, al secondo posto, figura un articolo dedicato agli errori presenti nell'opera di Dan Brown, [47] al quale sono state attribuite le seguenti parole chiave:

Ora, al di là delle solite voci asemantiche ("reference", "reviews") o di commento personale ("interesting", "toread"), ritroviamo almeno due tags volti a definire in modo più specifico il concetto ("critical", "mistakes"): e tuttavia questo tentativo è vanificato dall'impossibilità di dar vita a un soggetto composto, in grado di cioè di esprimere con pienezza il significato del documento, come può essere ad esempio "Da Vinci Code - mistakes".
Non v'è dubbio che, in questo come in altri casi, i taggers abbiano creato una pluralità di termini per esprimere il contenuto d'insieme, un po' come avviene nell'indicizzazione postcoordinata, nella quale a un documento vengono assegnati descrittori non collegati fra loro, in quanto la combinazione avviene a posteriori in base alla logica booleana. Nel mondo delle folksonomies però questo non è possibile: l'utente infatti non può ampliare o restringere la propria ricerca usando gli operatori logici, ma è costretto a impiegare termini singoli e disomogei, che difficilmente riescono a restituire il contenuto complessivo del documento.
Una riprova della validità della logica booleana si può avere inserendo in Google la combinazione "Da Vinci Code" "mistakes", poiché il sistema ha l'operatore AND predefinito: fatte salve le ridondanze tipiche dei motori di ricerca, la risposta risulterà infatti assai vicina a quella desiderata, dal momento che i primi dieci items visualizzati risultano decisamente pertinenti, e che fra essi vi è non solo una voce della Wikipedia dedicata all'argomento, ma lo stesso articolo da cui siamo partiti per questa analisi.
Passando a Technorati, ossia un sito che comprende "zilioni di foto, video, blog e altro", [48] vediamo che i tags relativi al Codice da Vinci sono pochi [49] e, come sempre, non particolarmente centrati. [50] Se comunque proviamo a entrare in una sua articolazione - ad esempio un blog in cui si discute della presenza nel romanzo dell'Opus Dei - ritroviamo la consueta sovrabbondanza terminologica, ovviamente priva di ogni forma di controllo o di collegamento fra le voci:

Ed è curioso che in questo contesto venga impiegata una delle espressioni più rilevanti dell'analisi semantica, e cioè "about": difatti il concetto di "aboutness" (o "circalità", com'è stato tradotto in italiano) indica tutto quello che è "circa, intorno, su" un documento, ciò di cui il documento parla effettivamente. [51] Ma al di là di questa sorprendente intuizione, ancora una volta sembra fallire il tentativo di esprimere un determinato contenuto attraverso le folksonomies; per contro, una forza semantica assai maggiore è presente nel titolo ("The Da Vinci Code & Opus Dei"), se si intende la congiunzione come una vera e propria "relazione di fase" - per dirla con Ranganathan - ossia la capacità di rappresentare in modo congiunto concetti appartenenti ad ambiti semantici diversi. [52]
E per concludere questo excursus torniamo a Flickr, in cui una ricerca effettuata con il nostro descrittore restituisce una quantità assai elevata di documenti ("6,035 results"); tra questi, piuttosto interessante appare un cluster riferito al "Da Vinci Code Overload", e cioè all'indotto, per così dire, che si è registrato in seguito successo del romanzo, come mostra la seguente fotografia:

E tuttavia le parole chiave assegnate a questo tema risultano concettualmente lontane dall'idea di "sovrabbondanza editoriale"; per contro, esse includono un acronimo ("BSOP"), che si scopre essere un link alla pagina dell'autrice della foto in questione, confondendo - direbbe un bibliotecario - il catalogo per autori con quello per soggetti. In conclusione, possiamo osservare che anche in questo caso il titolo appare di gran lunga più significativo dei descrittori che ad esso sono assegnati.
La nostra analisi, come si è visto, si è concentrata sui problemi semantici propri delle folksonomies, e quindi ha deliberatamente trascurato gli aspetti socioculturali che ad esse sono legati; un'indagine in quella direzione tuttavia non sarebbe stata inopportuna, e non solo per comprendere le motivazioni e i comportamenti del popolo dei taggers, ma per verificare l'entità del fenomeno e la sua diffusione in ambiti diversi da quelli finora presi in esame.
Sono infatti sempre di più gli organismi che decidono di adottare queste modalità, e fra questi anche le biblioteche le quali, forse obbedendo a un imperativo di ordine sociale, o forse per essere in linea con le parole d'ordine della Library 2.0, [53] si aprono con fiducia alle prospettive del tagging. Non pochi bibliotecari infatti sono convinti che le folksonomies possano costituire un importante mezzo di esplorazione e reperimento delle informazioni, sia perché non sono condizionate dalle rigidità dei tradizionali linguaggi di indicizzazione, sia perché impiegano un vocabolario più aperto e spontaneo, e dunque in grado di riflettere la mentalità e i gusti degli utenti: esse di conseguenza sembrano avere tutti i requisiti per affiancare - se non per sostituire - lo strumento per eccellenza di ricerca e recupero, e cioè il catalogo. [54]
Ed è proprio in base a queste considerazioni che Louise Spiteri propone di integrare i convenzionali cataloghi bibliotecari con le creazioni semantiche degli utenti: [55] questi ultimi infatti sono in grado di entrare sempre più in sintonia con le biblioteche, sfruttando attivamente le possibilità offerte dai loro siti web, e ottenendo servizi decisamente personalizzati. E tuttavia questo ruolo da protagonista si interrompe nel momento in cui gli utenti cercano di entrare nel cuore stesso del sistema - vale a dire il catalogo - per realizzare una propria categorizzazione, capace di riflettere le nuove esigenze conoscitive e comunicazionali di cui essi sono portatori.
Una risposta a queste esigenze, a parere di Spiteri, viene appunto dal tagging, che consente di aggiungere valore ai cataloghi delle biblioteche attraverso l'immissione di termini più duttili e rappresentativi della mentalità degli utenti: nelle parole dell'autrice,
le voci presenti nelle Library of Congress Subject Headings non sempre risultano intuitive per gli utenti. Le LCSH ad esempio utilizzano la voce "cookery", che molte persone probabilmente non sceglierebbero rispetto al più intuitivo "cooking", il quale è invece considerato un termine non preferito. Analogamente le LCSH usano "motion picture", laddove molti utenti sceglierebbero "film" o "movie" [...]. Inoltre, le LCSH non sembrano avere un vocabolario sufficientemente aggiornato per soddisfare i bisogni degli utenti; ad esempio il termine "RSS" non esiste nelle LCSH per esprimere il concetto di Really Simple Syndication. [56]
Il punto di vista dell'autrice dunque è che i tradizionali linguaggi documentari possono continuare a esercitare un proprio ruolo, anche se questo appare sempre più circoscritto a specifici ambiti disciplinari; essi invece sono incapaci di soddisfare le rinnovate esigenze degli utenti, a differenza di ciò che riescono a fare le folksonomies, che sono in grado di offrire un prezioso apporto in termini di elasticità semantica, oltre che di vicinanza al linguaggio e alla mentalità correnti.
Per verificare questa opinione, ci sembra allora interessante esaminare l'esperienza realizzata dalle biblioteche dell'università della Pennsylvania [57] le quali, di fianco a una ricca gamma di cataloghi, banche dati e altre risorse, offrono anche un tool costituito appunto dalle folksonomies. [58] E se entriamo in questa sezione, possiamo notare da un lato che i popular tags visualizzati sono quelli utilizzati almeno 65 volte dagli utenti, dall'altro che i termini composti sono collegati tramite underscore: e ciò equivale a un preciso tentativo di ridurre la dispersione propria di queste modalità, tanto da un punto di vista semantico (definendo in modo più accurato i soggetti composti), quanto sotto il profilo dell'uso, privilegiando i tags più impiegati dagli utenti. [59]
Ma se selezioniamo uno di questi tags (ad esempio "psychoanalysis"), vediamo che non tutti i documenti ad esso correlati ricadono nel campo tematico di riferimento, se è vero che fra i primi items connessi a questa voce compaiono i seguenti titoli:

Come sempre, i soggetti della Library of Congress ci forniscono una rappresentazione più oggettiva e precisa rispetto a quella che possono avere in mente gli utenti. E se si vuole un'ulteriore riprova di questo scarto fra un'indicizzazione "professionale" ed una "utenziale", possiamo rivolgerci a un prodotto che non nasce nelle biblioteche, ma che ad esse è esplicitamente rivolto: stiamo parlando della banca dati Engeneering Village. [60]
Si tratta di un fondamentale strumento di studio e di ricerca che copre tutti i settori dell'ingegneria, presentando articoli di riviste e atti di convegni per un totale di circa 7 milioni di record. [61] La banca dati ovviamente è dotata di un proprio sistema di controllo terminologico, dal momento che include ben due thesauri disciplinari (Compendex e Inspec); al tempo stesso però i suoi gestori hanno deciso di integrare questi strumenti con un nutrito gruppo di folksonomies realizzate dagli utenti, [62] come mostra l'immagine seguente:

[Figura 8]
Siamo in presenza di termini assai diversi da quelli squisitamente intuitivi e naïf che ritroviamo nei tags-sites esplorati in precedenza, poiché sono stati coniati da una comunità scientificamente coesa e padrona, per così dire, dei propri mezzi terminologici.
E se proviamo a selezionare uno di questi tags, e precisamente "nanoparticles", notiamo che a esso sono legati 11 documenti, ma non otteniamo altre informazioni. Se invece inseriamo la stessa voce nel thesaurus Compendex, non solo scopriamo che essa ha come termine associato (ossia come RT) il descrittore "microphase separation", ma che è gerarchicamente subordinata al BT "nanostructures", al quale peraltro sono connessi una serie di termini più ristretti (i NT "carbon clusters", "fullerenes", "microcrystals", "nanobelts", "nanocapsules", "nanoclusters", "nanocrystals", "nanoflowers", "nanoneedles", "nanorings", "nanorods", "nanosaws", "nanosheets", "nanospheres", "nanotips", "nanotubes", "nanowhiskers", "nanowires").
Ne risulta una struttura semantica chiaramente definita, che consente di ampliare o restringere la ricerca sulla base delle reali necessità dell'utente, di determinare con esattezza le voci composte, di eliminare omonimie, sinonimie e omografie, e di disambiguare i termini precisandone gli ambiti di riferimento. Oltre a ciò, l'impiego del thesaurus permette anche di visualizzare rapidamente i documenti legati ai diversi descrittori, non solo offrendo all'utente immediati riscontri "fattuali", ma fornendogli ulteriori informazioni sull'estensione semantica di queste voci (a "nanoparticles", ad esempio, sono legati 2602 records, a "nanosheets" 70, a "nanoflowers" 5, e così via [63]).
I due esempi riportati - quello relativo alle biblioteche dell'università della Pennsylvania e quello della banca dati Engeneering Village - possono allora costituire un primo punto di arrivo di questo nostro percorso, dal momento che in entrambi possiamo ritrovare una sostanziale diversità - epistemologica e cognitiva oltre che semantica - tra la modalità professionale di indicizzazione e la semplice assegnazione di contenuti da parte degli utenti.
Tale diversità non consiste solo nel fatto che la prima può giovarsi di un ricco corredo scientifico - oltre che di una consolidata tradizione - che le consente di pervenire agli esiti che conosciamo: in realtà, la differenza più rilevante risiede proprio nell'approccio decisamente oggettivo che essa assume nel momento in cui opera; e infatti non è un caso se l'indicizzatore acquisisce un abito mentale che lo porta ad essere "terzo e imparziale" fra l'autore e il lettore, [64] e che gli consente di escogitare le strategie più idonee per mettere in relazione le esigenze - conoscitive, linguistiche e comportamentali - dell'uno e dell'altro. Come ha scritto lucidamente Alfredo Serrai,
il procedimento di indicizzazione è induttivo: si basa cioè su delle ipotesi che il catalogatore fa rispetto agli interessi che l'utente potrà avere nei confronti di un certo documento. Ipotesi induttive sono, dall'altra parte, ossia dalla parte della consultazione, anche quelle che vengono escogitate e formulate dall'utente. Il rapporto fra le due ipotesi affinché avvenga l'incontro fra la ricerca e l'offera dovrebbe essere quello di una identità. [65]
Dunque è in questo best match fra conoscenze, opinioni e punti di vista dell'indicizzatore e dell'utente che possiamo riconoscere il cuore del problema, e che ci consente di concludere il nostro excursus proponendo una sospensione del giudizio - ed un necessario supplemento d'indagini - sull'ipotesi che vede l'utente investito del duplice un ruolo di creatore e fruitore dei contenuti.
Michele Santoro,Coordinamento dell'Area Scientifico-tecnica del Sistema Bibliotecario di Ateneo - Università di Bologna, e-mail michele.santoro@unibo.it
I riferimenti ai siti web sono controllati al 15 luglio 2007. Salvo diversa segnalazione, le traduzioni da testi stranieri sono nostre. L'autore ringrazia vivamente Claudio Gnoli, Serena Spinelli e Maurizio Zani per le preziose indicazioni fornite.
[1] Al riguardo assai significativi sono gli studi di Jean Piaget sullo sviluppo delle facoltà di classificazione e seriazione nei bambini; in essi infatti l'autore dimostra come fin dai primi anni di vita il bambino apprenda compiendo alcune azioni elementari come ammucchiare, separare, tracciare linee e così via; ciò si traduce in schemi di operazioni da cui derivano dati percettuali che vengono associati a insiemi diversi, dando vita a vere e proprie classificazioni. Di Piaget si veda tra l'altro La costruzione del reale nel bambino, Firenze, La Nuova Italia, 1973; Dal bambino all'adolescente: la costruzione del pensiero, passi scelti a cura di Ornella Andreani Dentici e Gioia Gorla, Firenze, La Nuova Italia, 1973; La causalità fisica nel bambino, introduzione di Guido Petter, Roma, Newton Compton, 1977.
[2] In lingua italiana, si rinvia in particolare ad alcune opere di Alfredo Serrai: Le classificazioni. Idee e materiali per una teoria e per una storia, Firenze, Olschki, 1977; Del catalogo alfabetico per soggetti. Semantica del rapporto indicale, Roma, Bulzoni, 1979; Dai "loci communes" alla bibliometria, Roma, Bulzoni, 1984; Storia della bibliografia, VII, Sistemi e tassonomie, a cura di Marco Menato, con un'appendice della storia della catalogazione delle stampe di Maria Cochetti, Roma, Bulzoni, 1997. Si veda inoltre Carlo Revelli, Il catalogo per soggetti, Roma, Bizzarri, 1970; Maria Chiara Giunti, Soggettazione, Roma, Associazione Italiana Biblioteche, 2001, p. 5-15. Si segnalano infine le voci Classification (a firma di Francis Miksa) e Indexing (redatta da Hans H. Wellisch), in Encyclopedia of library history, edited by Wayne A. Wiegand and Donald G. Davis, New York and London, Garland Publishing, 1999, rispettivamente alle p. 144-153 e 268-270.
[3] Al riguardo, si rinvia a un testo che costituisce una sintesi forse ineguagliata: Anthony C. Foskett, The subject approach to information, disponibile anche in lingua italiana con il titolo Il soggetto, traduzione di Leda Bultrini, Milano, Editrice Bibliografica, 2001.
[4] Su questi aspetti cfr. Riccardo Ridi, Nozioni di information retrieval, gennaio 2007, <http://lettere2.unive.it/ridi/info-retr.pdf>.
[5] Per una descrizione di questa nuova dimensione della rete e le sue implicazioni bibliotecarie si veda il recente articolo di Fabio Metitieri, Una seconda vita anche per le biblioteche? Second Life, un fenomeno in espansione con cui misurarsi, "Biblioteche oggi", 26 (2007), 4, p. 11-21.
[6] Nella sua suggestiva analisi in forma narrativa, Mario Rotta scrive che tale cambiamento "non aveva ancora un nome, fu chiamato solo 2.0, ma al di là di qualche aspetto meno significativo (o palesemente riciclato) aveva alcune caratteristiche specifiche, uniche... Almeno tre i fenomeni che si osservarono. 1) Personalizzazione: volevamo le "nostre" informazioni (Google News, RSS), avevamo bisogno di strumenti per costruire i "nostri" percorsi e accumulare conoscenze... 2) Immediatezza: volevamo 'trovare' più che cercare. Interrogando la rete in linguaggio naturale, collocando le informazioni nello spazio (georeferenzialità), o 'fuori' dal tempo (podcasting). E poi c'era anche chi aveva bisogno di una 'seconda vita'...; 3) Socializzazione: Sentivamo il bisogno di raccontarci (blogging), di navigare insieme (co-browsing), di condividere i nostri segnalibri e le nostre etichette (social bookmarking), di dare un senso alle informazioni sapendo che 'altri' le utilizzavano... In questa prospettiva cambiava soprattutto la relazione tra utenti e informazioni: non bastava più saper navigare o imparare a cercare, bisognava cominciare a "trovare" (Mario Rotta, Content is dead, long live the content, <http://www.mariorotta.com/scritture/wp-content/uploads/2007/05/mrslides20070330v2.pdf>.
[7] Mario Montalto, Web 2.0: Internet volta pagina. Arriva la versione 2.0 di Internet, un'evoluzione tanto tecnologica quanto filosofica, novembre 2005, <http://www.microsoft.com/italy/pmi/marketing/internetmarketing/web20.mspx>.
[8] Sull'impatto di questi nuovi strumenti cfr. le osservazioni presenti nella voce Folksonomies della Wikipedia, in particolare la sezione Criticism: <http://en.wikipedia.org/wiki/Web_2#Criticism>.
[9] Oggi in realtà qualcuno parla già di Web 3.0: "Un'interessante definizione di Web 3.0 proviene da Derrick De Kerckhove, direttore del McLuhan Program dell'Università di Toronto, secondo il quale la rete del futuro funzionerà come il cervello umano, sfruttando le capacità di due emisferi opposti e complementari, realizzando in rete la bipolarità emisferica del nostro cervello. L'emisfero destro sarebbe il Web 2.0, sintetico e associativo, mentre il Web semantico, analitico e preciso, coinciderebbe con l'emisfero sinistro. Più in generale l'idea di Web 3.0 è che la catalogazione operata dai network sociali sul sapere che circola in rete, diventi più consapevole e razionale dando ragione a chi in passato aveva proposto l'utopia di un web semantico, fallendo per mancanza di supporto popolare. Su Apogeonline si trova un'interessante articolo di Bernardo Parrela che sottolinea come l'implementazione del Web 3.0 sia ancora un miraggio" (Andrea De Marco, Web 3.0 oppure Web 2.1? Linguaggi di ontologie, 31 Maggio 2007, <http://corsodicrm.wordpress.com/tag/web-30/>).
[10] Si leggano ad esempio le seguenti affermazioni: "Web 2.0 si riferisce alle tecnologie che permettono ai dati di diventare indipendenti dalla persona che li produce o dal sito in cui vengono creati [...]. Il Web 2.0 è costruito con tecnologie come Ajax, un approccio di sviluppo web basato su JavaScript ed il linguaggio di programmazione XML. Questa miscela di tecnologie permette alle pagine di funzionare più come applicazioni per il desktop che come pagine di contenuto statico antiquate. [...]. Il web 2.0 prospera su di un'altra bellissima tecnologia di nome RSS. [...]. Il potere delle open API fornisce alla rivoluzione del web 2.0 l'accesso ad ampi database informativi", e così via (Cos'è il Web 2.0: definizione e mini-guida di Robin Good, <http://www.masternewmedia.org/it/Web_2.0/scopri_tutti_gli_usi_e_le_occasioni_di_business_del_Web_2.0_20050710.htm>).
[11] Olivier Le Deuff, Folksonomies. Les usagers indexent le web, "Bulletin des Bibliothèques de France", 51 (2006), 4, <http://bbf.enssib.fr/sdx/BBF/frontoffice/2006/04/document.xsp?id=bbf-2006-04-0066-002/2006/04/fam-apropos/apropos&statutMaitre=non&statutFils=non>.
[12] Su queste problematiche si vedano le stimolanti riflessioni di Riccardo Ridi, Metadata e metatag: l'indicizzatore a metà strada fra l'autore e il lettore, in The digital library. Challenges and solutions for the new millenium, Bologna, June 17-18, 1999, <https://www.aib.it/aib/commiss/cnur/dltridi.htm>.
[13] Rinviamo in particolare al recente articolo di Nicola Benvenuti, il primo su questo argomento - a quanto ci consta - pubblicato su una rivista professionale italiana, e che costituisce una notevole apertura di credito verso queste modalità (Nicola Benvenuti, Social tagging e biblioteche. Implicazioni e suggestioni di una 'classificazione generata dagli utenti che emerge attraverso un consenso dal basso', "Biblioteche oggi", 25 (2007), 3, p. 35-42).
[14] Isabel de Maurissens, Folksonomy: una classificazione sociale del web. Dal caos originario ai frutti della collaborazione, "IR-Innovazione e Ricerca", 2006, <http://eprints.rclis.org/archive/00007574/> (citazione leggermente modificata).
[15] Tassonomia, in Wikipedia, l'enciclopedia libera, <http://it.wikipedia.org/wiki/Tassonomia>.
[16] Non pochi osservatori in verità si sono accorti di questo vizio d'origine; in particolare Peter Merholz ha proposto di sostituire l'erroneo "folksonomy" con "ethnoclassification", termine coniato nel 1996 da Susan Leigh Star e "riferito al modo in cui le persone classificano e categorizzano il mondo attorno a loro" (Susan Leigh Star 1996, Slouching toward infrastructure, Digital Libraries Conference Workshop, Illinois Research Group on Classification, Graduate School of Library and Information Science, University of Illinois, 1996, <http://is.gseis.ucla.edu/research/dl/star.html>). Il contributo di Merholz, Metadata for the masses, risale all'ottobre 2004, ed è disponibile all'indirizzo <http://www.adaptivepath.com/publications/essays/archives/000361.php>. Al riguardo si veda anche Ethnoclassification: faceted tagging, "Speechless", June 16th, 2007, <http://oceanflynn.wordpress.com/2007/06/16/ethnoclassificationfaceted-tagging/>.
[17] Eric J. Hunter, Classification made simple, Aldershot, Gower, 1988, p. 4 (gli esempi riportati sono tratti dalla stessa pagina di questo volume).
[18] E infatti non è un caso se il sito prende il nome di Library Thing, <http://www.librarything.com/>.
[19] Trascuriamo per ora l'effettiva "pertinenza" dei termini individuati rispetto al concetto che si vuol esprimere, su cui torneremo successivamente.
[20] Difatti il diverso "corpo" tipografico con cui sono visualizzati i tags non è rappresentativo di relazioni semantiche fra i termini, ma solo del numero di items collegati a ciascun tag.
[21] Elaine Peterson, Beneath the metadata. Some philosophical problems with folksonomy, "D-Lib Magazine, 12 (2006), 11, <http://www.dlib.org/dlib/november06/peterson/11peterson.html>.
[22] Si veda al riguardo il contributo - tuttora insuperato - di Vilma Alberani, Classificazione, in Documentazione e biblioteconomia, Manuale per i servizi di informazione e le biblioteche speciali italiane, a cura di Maria Pia Carosella e Maria Valenti, presentazione di Paolo Bisogno, Milano, Franco Angeli, 1989, p. 171-246.
[23] Fra la numerosa documentazione disponibile al riguardo, rinviamo esclusivamente a Claudio Gnoli, Classificazione a faccette, Roma, Associazione Italiana Biblioteche, 2004.
[24] Clay Shirky, Ontology is overrated: categories, links, and tags, "Economics & Culture, Media & Community", 2005, <http://www.shirky.com/writings/ontology_overrated.html>.
[25] Ibid.
[26] Emanuele Quintarelli, Folksonomies: power to the people, paper presented at the ISKO Italy-UniMIB meeting, Milan, June 24, 2005, <http://www.iskoi.org/doc/folksonomies.htm>.
[27] Ibid.
[28] Analoghi punti di vista si ritrovano in Adam Mathes, Folksonomies. Cooperative classification and communication through shared metadata, December 2004, <http://www.adammathes.com/academic/computer-mediated-communication/folksonomies.html>; Louis Rosenfeld, Folksonomies? How about metadata ecologies?, January 06, 2005, <http://www.louisrosenfeld.com/home/bloug_archive/000330.html>; Robert Fox, Cataloging for the masses, "OCLC Systems & Services: International digital library perspectives", 22 (2006), 3, p. 166-172; Thomas Vander Wal, Beneath the metadata - Replies, "Personal InfoCloud", november 20, 2006, <http://www.personalinfocloud.com/2006/11/beneath_the_met.html>.
[29] Chi scrive ha in più occasioni affrontato questo argomento; ci permettiamo dunque di rinviare a La disarmonia prestabilita. Per un apprccio ibrido alla conoscenza e ai suoi supporti, "Biblioteche oggi", 20 (2002), 5, p. 46-57, <http://www.bibliotecheoggi.it/2002/20020504601.pdf>, poi in La biblioteca ibrida. Verso un servizio informativo integrato, a cura di Ornella Foglieni, Milano, Editrice Bibliografica, 2003, p. 59-78; Sulle spalle dei giganti. Riflessioni ex-post su una proposta di interpretazione, "Biblioteche oggi", 21 (2003), 1, p. 21-30, <http://www.bibliotecheoggi.it/2003/20030102101.pdf>; Biblioteche e innovazione. Le sfide del nuovo millennio, Milano, Editrice Bibliografica, 2006.
[30] Un interessante esempio viene dall'elaborazione condotta da un gruppo di lavoro dell' International Society for Knowledge Organization (ISKO), e volta a individuare forme di classificazione basate non più sulle discipline ma sulle teorie e sui fenomeni; si veda al riguardo Claudio Gnoli - Rick Szostak, The León manifesto, 2007, <http://www.iskoi.org/ilc/leon.htm>.
[31] Nelle parole di Thomas Vander Wal, non è importante "chi categorizza meglio di me, ma chi categorizza come me" e dunque, commenta Nicola Benvenuti, "chi ha valori e interessi simili ai miei" (Nicola Benvenuti, cit., p. 38).
[32] Isabel de Maurissens, cit.
[33] Nicola Benvenuti, cit., p. 36.
[34] Ibid, p. 36.
[35] Ibid. Difatti, prosegue l'autore, per tentare di risolvere questi problemi sono state sperimentate varie tecniche come il raggruppamento, automatico o indotto manualmente, dei tag per definire "faccette" che in effetti realizzano servizi di ricerca efficaci ma solo in ambiti estremamente circoscritti e ben definiti" (p. 36-37).
[36] Ulises Ali Mejias, Tag literacy, "Ideant", April 26, 2005, <http://ideant.typepad.com/ideant/2005/04/tag_literacy.html>.
[37] Marieke Guy - Emma Tonkin, Folksonomies: tidying up tags?, "D-Lib Magazine", 12 (2006), 1, <http://www.dlib.org/dlib/january06/guy/01guy.html>.
[38] Ibid.
[39] Al riguardo, un'equilibrata analisi è sviluppata da Alireza Noruzi, Folksonomies: (un)controlled vocabulary?, "Knowledge Organization", 33 (2006), 4, p. 199-203.
[40] Cosa che avviene piuttosto frequentemente sulla rete, come testimonia fra l'altro la ricca raccolta di recensioni presente su Amazon.
[41] Ancora più sorprendente è il fatto che, per far ciò, le persone siano disposte a pagare una tariffa: difatti il sito permette agli utenti di assegnare tags gratuitamente ai primi 200 libri; qualora se ne vogliano attribuire di più, le tariffe sono di 10 dollari per anno, o di 25 dollari per un'indicizzazione illimitata.
[42] Per rumore, com'è noto, si intendono tutti i documenti non rilevanti ottenuti a seguito di una ricerca.
[43] F. Wilfrid Lancaster, Indexing and abstracting in theory and practice, London, The Library Association, 1991, in particolare il capitolo 12, intitolato On the indexing and abstracting in imaginative works, p. 182-192. Sull'indicizzazione semantica della fiction si rinvia anche a Claudio Gnoli, C'era una volta un soggetto, di prossima uscita su "AIB Notizie".
[44] Avendo letto di recente il romanzo, proviamo un po' per celia a elaborare i seguenti soggetti (una stringa coestesa, in questo caso, sarebbe impossibile), tenendo conto che si tratta di informazioni assolutamente "non sostantive": 1. Gesù Cristo - Fondazione della Chiesa - su Maria Maddalena; 2. Chiesa Cattolica - Verità storica - Occultamento; 3. Priorato di Sion - Verità storica - Ristabilimento.
[45] Flickr, <http://www.flickr.com/>.
[46] del.icio.us, social bookmarking, <http://del.icio.us/>.
[47] Tracy V. Wilson, How the Da Vinci Code doesn't work, "Howstuffworks", <http://entertainment.howstuffworks.com/davinci-code.htm>.
[48] Technorati, <http://technorati.com/>.
[49] I tags relativi sono infatti i seguenti: "dan brown, jesus, da vinci code, religion, movie, movies, tom hanks, books, christianity, google".
[50] Basti pensare a tags quali "Tom Hanks", l'attore interprete del film tratto dal romanzo, per averne un'idea.
[51] Cfr. in particolare Alfredo Serrai, Del catalogo alfabetico per soggetti, cit.; dello stesso autore è anche la traduzione del termine aboutness con circalità.
[52] Al riguardo si rinvia al nostro Ripensare la CDU. Per una riflessione sulla storia, il ruolo e le prospettive della Classificazione Decimale Universale, "Biblioteche oggi", 13 (1995), 8, p. 48-57, <https://www.aib.it/aib/contr/santoro1.htm>.
[53] Si veda fra l'altro Fabio Metitieri, La biblioteca come conversazione. A colloquio con David Lanks, "Biblioteche oggi", 25 (2007), 5, p. 15-22 (disponibile anche, in versione più ampia e in lingua inglese, all'indirizzo <http://www.bibliotecheoggi.it/2007/20070501501.pdf>); Fabio Di Giammarco, Library 2.0, ovvero la centralità dell'utente. Le biblioteche si confrontano con l'evoluzione del Web, "Biblioteche oggi", 25 (2007), 5, p. 23-25.
[54] Cfr. ad esempio Ellyssa Kroski, The hive mind: folksonomies and user-based tagging, "Infotangle", 12/07/2005, <http://infotangle.blogsome.com/2005/12/07/the-hive-mind-folksonomies-and-user-based-tagging/>.
[55] Louise F. Spiteri, The use of folksonomies in public library catalogues, "The Serial Librarian", 51 (2006), 2, p. 75-89. Della stessa autrice si veda anche Structure and form of folksonomy tags: the road to the public library catalogue, "Webology", 4 (2007), 2, <http://www.webology.ir/2007/v4n2/a41.html>.
[56] Louise F. Spiteri, The use of folksonomies in public library catalogues, cit., p. 76.
[57] Penn Libraries, <http://www.library.upenn.edu/>.
[58] Penn tags, <http://tags.library.upenn.edu/>.
[59] Un'altra iniziativa che ha portato molto avanti il discorso sulla definizione dei termini composti è Connotea: si tratta di un sito di scholarly bookmarking (ossia di condivisione in rete di pagine web ed altre risorse scientificamente rilevanti) sviluppato dal gruppo "Nature", in cui è possibile inserire descrittori formati da più parole separate fra loro da virgolette e/o da virgole, come ad esempio: genetics "DNA structure" history, oppure: "C. elegans", "neuromuscular development". Al riguardo cfr. Connotea. Organize. Share. Discover, <http://www.connotea.org/>. Sul tema degli sviluppi in senso controllato delle folksonomies e la loro relazione con le faccette in senso lato, si veda poi il progetto italiano Facetag, <http://facetag.org>.
[60] La banca dati è presente fra le risorse elettroniche acquisite dall'università di Bologna, <http://www.biblioteche.unibo.it/risorse-elettroniche/banche-dati>.
[61] Al riguardo si veda Maurizio Zani, Engineering Index, ovvero il mondo che abbiamo perduto. Il caso esemplare delle trasformazioni subite in oltre un secolo di vita da uno dei più importanti strumenti di informazione bibliografica in ambito scientifico, "Biblioteche oggi", 20 (2002), 5, p. 6-16, <http://www.bibliotecheoggi.it/2002/20020500601.pdf>.
[62] Cfr. Engeneering Village introduce record tagging, New York, 22 February 2007, <http://www.ei.org/news/news_2007_02_22.html>.
[63] Il sistema ovviamente permette di raffinare la ricerca attraverso gli operatori booleani e gli altri meccanismi di filtro.
[64] Desumiamo questa nozione da Riccardo Ridi, per il quale l'indicizzatore "svolge un ruolo terzo fra autore e lettore, fungendo da intermediario fra docuverso e utenti, ottimizzando così l'incontro fra domanda e offerta informativa" (Riccardo Ridi, Metadata e metatag: l'indicizzatore a metà strada fra l'autore e il lettore, cit.).
[65] Alfredo Serrai, Dai "loci communes" alla bibliometria, cit., p. 26.
![]()
![]()
![]()